about me
个人简介
introduction
Graduated from ZheJiang University in 2020 as a Full-time undergraduate, majored in EE/CS;
Software engineer with 5 years+ working experience including
- High-Performance and Virtualized Network Development in Cloud Computing; Full-stack development in k8s cni
- Industrial embedded software development on microprocessors Like Arm-M like soc
- Kernel And Qemu enthusiast
contact me
Email: 3160104094@zju.edu.cn
关于本项目
-
定位为一个技术笔记,记录过程是主要目的。 包含了我目前的工作方向: k8s, cni, 虚拟化, linux kernel以及我想学习的领域,比如 llm, web3, 量化,etc…
-
这个项目的内容会很杂,我会尽量把它做的全。
-
欢迎讨论和提出修改意见,link
ysyx
记录一下我参加 https://ysyx.oscc.cc/ 项目的学习过程
预学习
F.1
基础情况介绍
先要做一个通识问卷, 讲诉一生一芯的一些基本情况。
提问的技巧
嗯,这个很好。可能在学校里问老师多蠢的问题都可以,但是去社会上这个干很可能会导致自己人缘不好。 写了一些感想:
提问是双向的,对于已经工作的人来说,更是如此。对于一个问题,如果没有仔细思考过/尝试过就把它抛给别人,是很不负责的,往远了说,这种人的人际关系也是不咋地的。 对于一个问题,首先应该去自己思考,方式包括 STFW, RTFM, RTFSC,当然,现在还包括问AI。但不建议一上来就问AI,因为万一出现了幻觉现象,可能会导致后面的努力全白费,对于一个问题,应该有一些最基础的认知,再进行后续的工作,会使得对方(无论是ai或者资深工程师)产生错误输出的概率低很多。
F.2
logisim 安装与使用
在我的mac电脑上通过 wget https://github.com/logisim-evolution/logisim-evolution/releases/download/v4.1.0/logisim-evolution-4.1.0-aarch64.dmg 然后就能够顺利运行了。
三个实验
- 阅读guide
然后通过 RTFM 实现了教程中的两个电路。
-
io library
- button: 开关,和输出好像差不多
- DIP switch: 文档好像没有,应该是拨码器
- joystick: 两个若干bit的数据,(x,y)代表这个杆子的位置
- led: 灯
- led rgb: rgb 灯
- keyboard: 键盘
- 7-segment Display: 数码管
- hex digit display: 16进制数码管
- led matrix: led 矩阵
- tty: 串口
-
实现有趣的电路
说实话,没有什么想法,先留空吧。
F.3 数字电路基础
前言:大学里学过数电,所以对我来说可能更多的是复习,笔记不一定很全。但是学的时间很久了,大概八年前,所以实验作业也不一定对,仅供参考。
后面发现可以记录工作,于是把作业都放这儿
基础门电路
实验
- 分析门电路

| A | B | Y |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 0 |
我记得有个什么方法可以算这种的,但现在忘了,好在这里一眼就看出来了。应该叫它或非门。
Y = ~(A|B) or Y = (~A) & (~B)
-
设计或门 只需要在上面的实验输出后面再加上一个非门,就可以实现或门。
-
分析三输入与非门晶体管数量
方案一: 通过一个与门与一个与非门实现。按照前面的课程,一个与门需要6个晶体管,一个与非门需要4个晶体管,那么一共需要10个晶体管。
方案二: 通过晶体管搭建。需要6个晶体管。
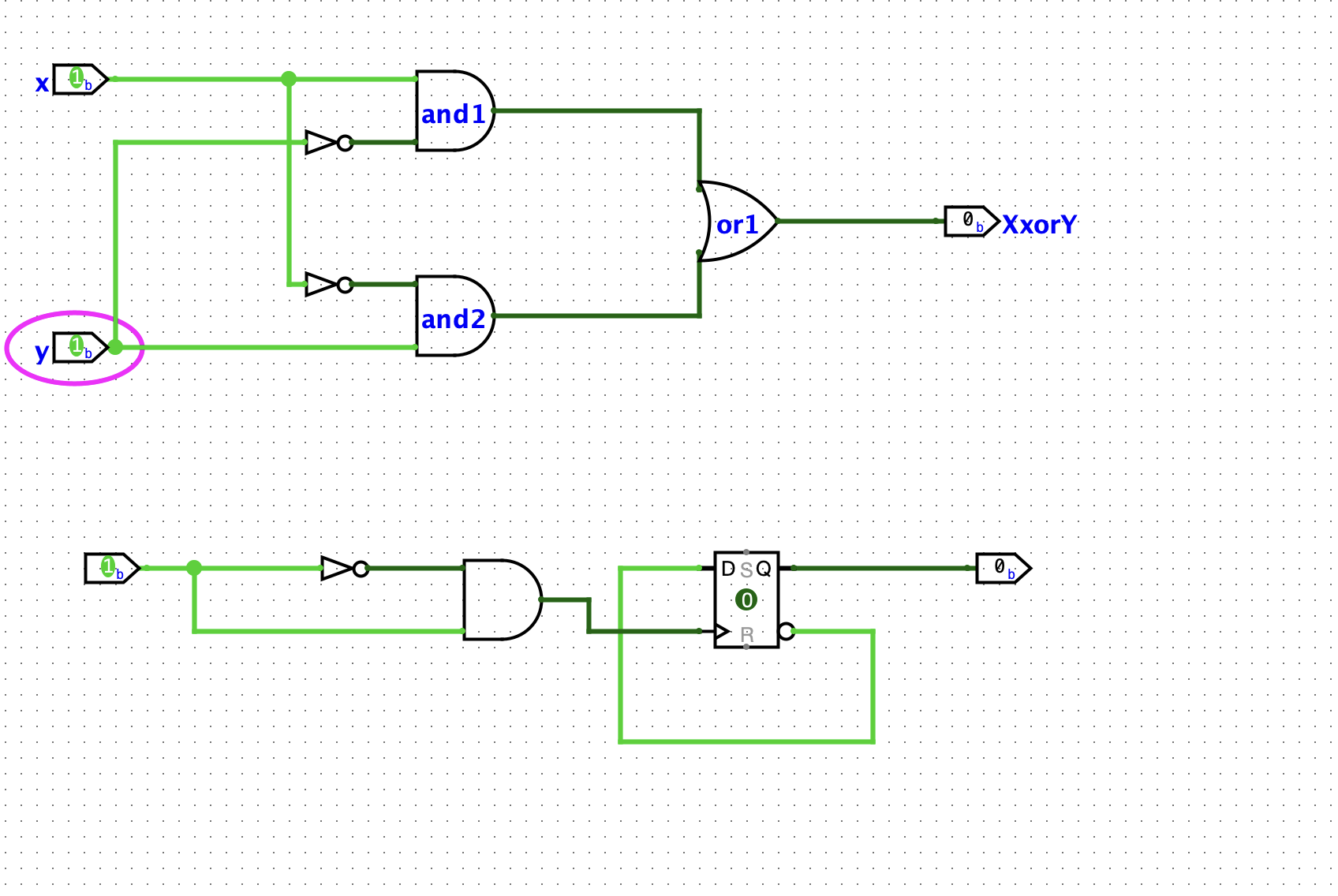
- 搭建异或门及对应晶体管数量
这个在我F.2的guide阶段就已经做了,所以就不重复了。用了两个非门,两个与门,一个或门。按照我们实现的或门(或非门+非门=5个晶体管)来算的话,一共用了 2 * 1 + 6 * 2 + 5 = 19 个晶体管。
- 搭建同或门
可以简单的通过在 异或 门后面加一个 非门,但是我想通过真值表来试试看先。
| A | B | C |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
算出来 Y=(~A&~B)|(A&B)
理论知识
- 真值表
原来我前面不知不觉中使用的方法是叫真值表,而通过真值表得出逻辑表达式的方法如下:
对所有输出为1的表项,将将每一个输入都变为1(取反或者不取反)后,进行或操作就是我们需要的表达式。
为什么是对的?因为输出要么为0,要么为1。将所有可能使得输出为1的可能进行 合并(或) 操作之后,得到的就是正确的表达式了。
二进制和十六进制
这个我会,就不记了。
组合逻辑电路
译码器
2-4 译码器
首先求出 Y0-Y3 的输出。
Y3 = A1 & A0
Y2 = A1 & ~A0
Y1 = ~A1 & A0
Y0 = ~A1 & ~A0
搭建如下,加了一个使能脚,主要是为了后面的3-8译码器使用

子电路功能
看 2-4 译码器扩展为 3-8 译码器的操作。就是一个 circuit 作为一个模块。
把2-4译码器拓展为3-8译码器
搭建如下,同样的,也有一个使能脚。

转码器 - 是一种特殊的译码器
定义: 可以按照指定的规则将一种编码的输入转换成另一种编码的输出。
七段数码管译码器1
下面是七段数码管的引脚与显示的对应关系图。
a
---
f| g |b
---
e| |c
--- .h
d
得出真值表
| 数字 | b3 | b2 | b1 | b0 | a | b | c | d | e | f | g | h |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 |
| 4 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 |
| 5 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 |
| 6 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| 7 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 8 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 9 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 |
| 其它 | x | x | x | x | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
求出值关系
n0 = (~b3&~b2&~b1&~b0)
n1 = (~b3&~b2&~b1&b0)
n2 = (~b3&~b2&b1&~b0)
n3 = (~b3&~b2&b1&b0)
n4 = (~b3&b2&~b1&~b0)
n5 = (~b3&b2&~b1&b0)
n6 = (~b3&b2&b1&~b0)
n7 = (~b3&b2&b1&b0)
n8 = (b3&~b2&~b1&~b0)
n9 = (b3&~b2&~b1&b0)
# 可以看出来,就是一个 4-16 译码器,我用两个 3-8 译码器搭起来
a = n0 | n2 | n3 | n5 | n6 | n7 | n8 | n9
b = n0 | n1 | n2 | n3 | n4 | n7 | n8 | n9
c = n0 | n1 | n3 | n4 | n5 | n6 | n7 | n8 | n9
d = n0 | n2 | n3 | n5 | n6 | n8 | n9
e = n0 | n2 | n6 | n8
f = n0 | n4 | n5 | n6 | n8 | n9
g = n2 | n3 | n4 | n5 | n6 | n8 | n9
h = ~(n0|n1|n2|n3|n4|n5|n6|n7|n8|n9)
最终搭建的电路如下:

七段数码管译码器2
基于上面的再做拓展,就简单了。
'''
a
---
f| g |b
---
e| |c
--- .h
d
'''
# for i in range(16):
# ni = 4_16_decoder(i)
# a-g 保持和上面的不变,h 没有用
# 增加使得对应管子亮的数字就行了
a = a | n10 | n12 | n14 | n15
b = b | n10 | n13
c = c | n10 | n11 | n13
d = d | n11 | n12 | n13 | n14
e = e | n10 | n11 | n12 | n13 | n14 | n15
f = f | n10 | n11 | n12 | n14 | n15
g = g | n10 | n11 | n13 | n14 | n15

总体上来说就是加了一个hex拓展。
有一个hex_enable的pin,当使能的时候,> 9 的输入会让晶体管显示 A ~ F.
不使能的时候,> 9 的输入会让晶体管显示为一个点。
编码器
16-4 编码器
啊,这里求真值表就过于复杂了。 从数字0-15, 列举下每一位下出现的bit就可以了。
Y0 = A1 | A3 | A5 | A7 | A9 | A11 | A13 | A15
Y1 = A2 | A3 | A6 | A7 | A10 | A11 | A14 | A15
Y2 = A4 | A5 | A6 | A7 | A12 | A13 | A14 | A15
Y3 = A8 | A9 | A10 | A11 | A12 | A13 | A14 | A15
搭建如下:

4-2 优先编码器
我一开始的想法是当高位有输入的时候,低位不管是什么都无效。所以我把低位的输入全都 & 了高位的 输入。
这样,当高位有输入时,低位的输入无效,就实现了 优先 的概念。

后面去参考了网上的资料。发现可以用下面的表达式实现
Y1 = a3 | a2
# 下面这个的意思就是说,当a2 为1,且a1为1的时候,Y0 不能为1,4-2优先编码 也就这一种特殊情况
Y0 = a3 | (~a2 & a1)
搭建为如下:

16-4 优先编码器
想法是这样的,先把16位数据分成4组。b15-b12,b11-b8,b7-b4,b3-b0。然后依次将它们通过一个4-2优先编码器。
很显然,当b15-b12 有数值A3时,结果应该输出 0xc + A3
否则当 b11-b8 有数值A2时,结果应该输出 0x8 + A2
否则当 b7-b4 有数值A1时,结果应该输出 0x4 + A1
否则当 b3-b0 有数值A0时,结果应该输出 0 + A0
0xc,0x8,0x4,0x0就是 (0x3,0x2,0x1,0x0) <<2 。就是把高组的是否有输出进行一次优先编码。
实现如下: 4-2 编码器加了 V 输出,就是对4个输入进行一次或

前导0/1的计算
- 前导0的计算:
优先编码器会给出最高位1的数值编码,所以只需要用 输出位数 - 这个数值 就是前面有多少个0的结果了。
比如说 4-2 优先编码器对 0100 的处理结果为 2,只需要用 0b11 - 0b10 就得出来 1的结果。
- 前导1的计算:
先取反,然后计算前导0就行了。
多路选择器
1位2选1选择器
这里给出我对这种命名方式的理解:
m位 n选1选择器
代表每一个输入有m位,共 n 个输入,从其中选出一个作为输出,输出也有m位。

3位4选1选择器
3位4选1选择器 就是4个3位输入,从中选出一路作为输出。
具体实现如下:

可切换进位计数制的七位选择器
这个实际上在我带有 hex 拓展的选择器中就已经做出来了。
这里的思路是,若干个1位2选1选择器。选择信号为拨码开关最高位。其它信号定义为如下:
h = h if s == 0 else 0
Ai = Ai if s == 1 else 0 # (15>=i>=10)
实现在这儿
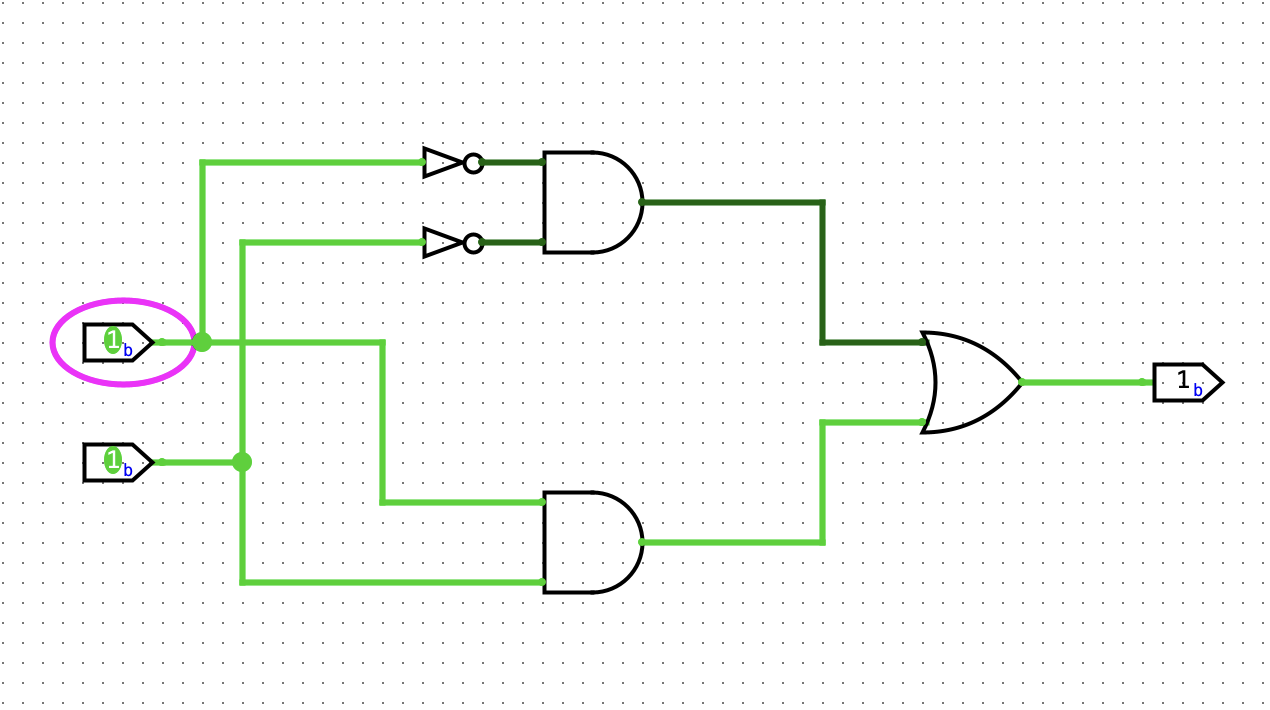
搭建4位比较器
如果两个4位二进制数相同,那么点亮LED灯。

加法器
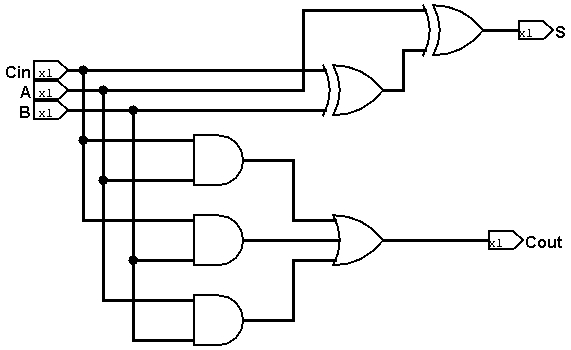
搭建1位全加器
真值表
| A | B | Cin | S | Cout |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
由此可以得出关系
S = A ^ B ^ Cin
Cout = (A&B) | (B&Cin) | (A&Cin)
搭建如下:
用1位半加器搭建1位全加器
先搭建出来半加器

用数学进行分析:
- 首先 A 和 B 进行半家,得到进位C1和S1
- S1要输入Cin再次进行一次半加,得到进位C2和S2
- 最终的S肯定为S2,而最终的C可以是C1和C2半加结果的S,也可以是C1|C2(因为C1和C2肯定不会同时为1),也可以是C1^C2。
我这里最终的C是从C1和C2的半加来的。

搭建4位全加器和校验

整数的机器码表示
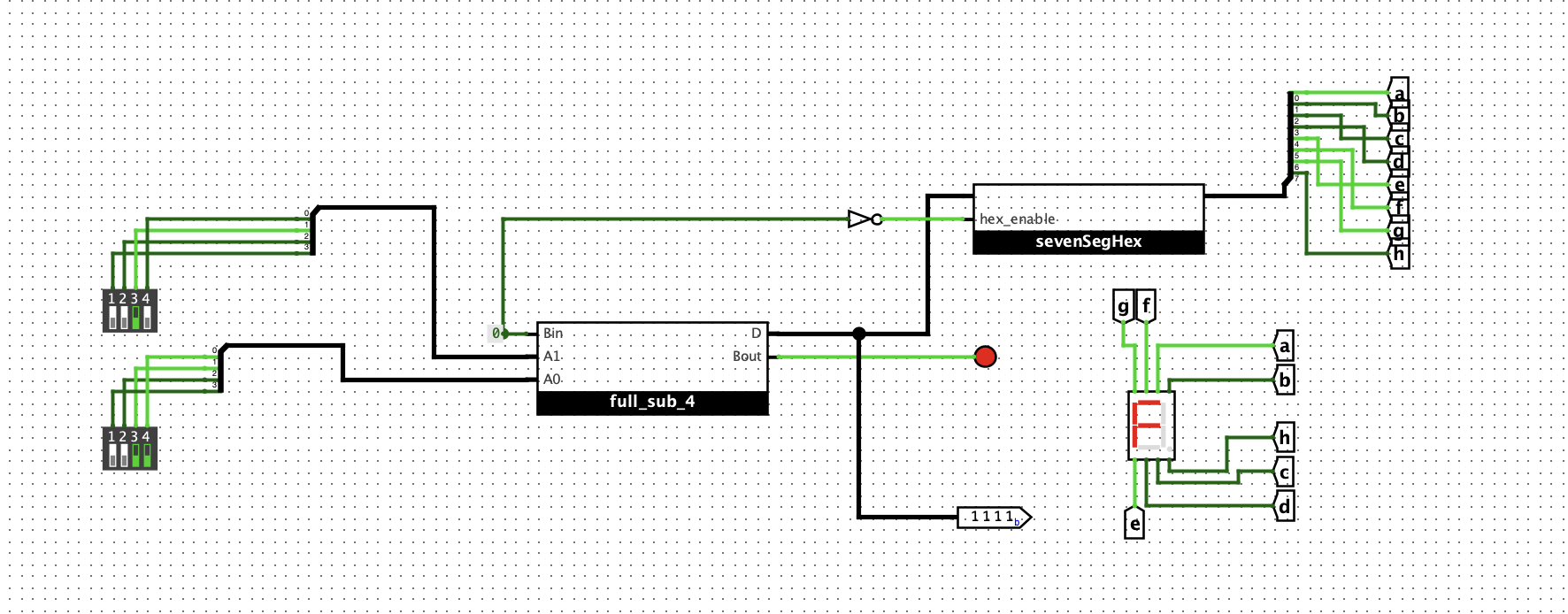
4位减法器
参考4位加法器,得先设计一下1位减法器(a1-a0-borrow)。写出真值表
| A1 | A0 | Bin | D | Bout |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 |
得出关系:
D = (~A1 & ~a0 & bin) | (~A1 & a0 & ~bin) | (A1 & ~a0 & ~bin) | (A1 & a0 & bin)
bout = (~A1 & ~a0 & bin) | (~A1 & a0 & ~bin) | (~A1 & a0 & bin) | (A1 & a0 & bin)
搭建出一位全减器,如下:

然后搭建出4位全减器,如下:

验证如图:
0x2 - 0x3 = 0xf, borrow 1
4位原码加法器
按照前面几种情况的分析,计算原码时,首先要选出符号位,然后对剩下的数据位,要么进行加,要么进行减。
具体规则是:
- 两个正数AB相加: 数据位A3+B3,符号位为0 (00)
- 大正数A加小负数B: 数据位A3-B3,符号位为0 (01)
- 小正数A加大负数B: 数据位B3-A3,符号位为1 (10)
- 两个负数相加,数据位A3+B3,符号位为1 (11)
- 这里假设了A一定是正数,当A不是正数时,就把A和B换个顺序
这样的话,按下面的进行设计:
- 先把输入进行选择,在输入有正数时,A永远是正数
- 计算出 A3+B3, A3-B3, B3-A3
- 拼凑一下四种输出结果
- 拿出(A4与B4),组合成为 B4A4, 作为选择子,对四种结果进行选择。
设计如下:

验证如下:
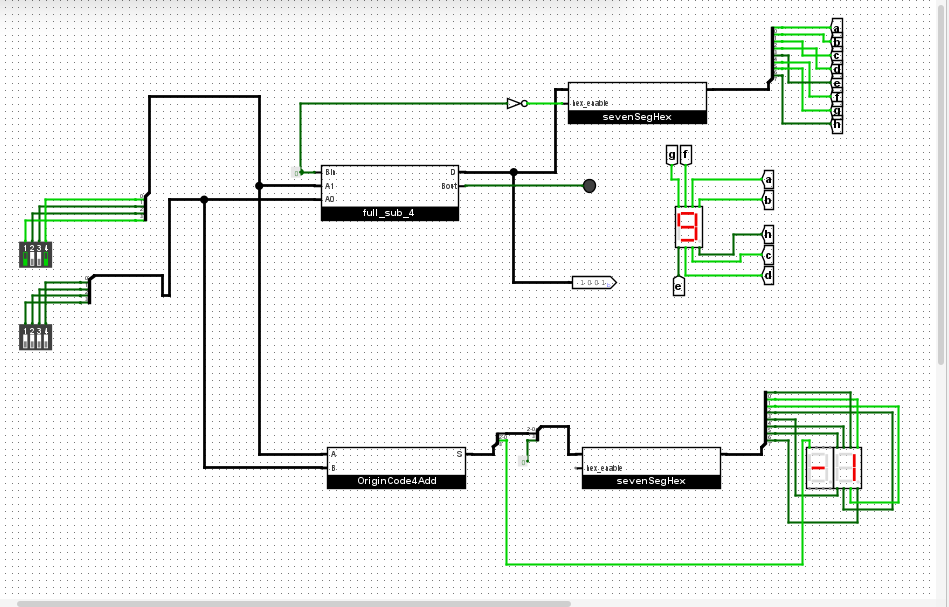
四位反码加法器
按照思路: 先把反码转换为真值等价的原码,然后使用原码加法器计算结果, 再将结果转换为真值等价的反码进行设计。
结果如下:

搭建4位反码加法器(2)
嗯,发现如果是负数的情况下,RCA所得结果再加一个1就是正确结果了。
这就是补码的概念吧。这里就不做了。
补码的疑问
教材中这段证明对我来说很突兀,这是尝试在说明什么问题呢?

问了 AI 之后,给出的解答是,这是在证明,为什么补码能够正确表示一个数的值。
当前正确表示也是有前提的,前提是这个补码最高位(符号位) 要被视为 -2^(n-1) * B(n-1)
检测补码加法是否发生溢出
先得出完整的真值表:
| An-1 | Bn-1 | Cn-1 | Cn | Sn-1 | 溢出 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 否 |
| 0 | 0 | 1 | 0 | 1 | 是 |
| 0 | 1 | 0 | 0 | 1 | 否 |
| 0 | 1 | 1 | 1 | 0 | 否 |
| 1 | 0 | 0 | 0 | 1 | 否 |
| 1 | 0 | 1 | 1 | 0 | 否 |
| 1 | 1 | 0 | 1 | 0 | 是 |
| 1 | 1 | 1 | 1 | 1 | 否 |
所以 溢出= An-1&Bn-1&~Sn-1 | ~An-1&~Bn-1&Sn-1
搭建如下:

时序逻辑电路
SR 锁存器
如下

oscillation apparent:
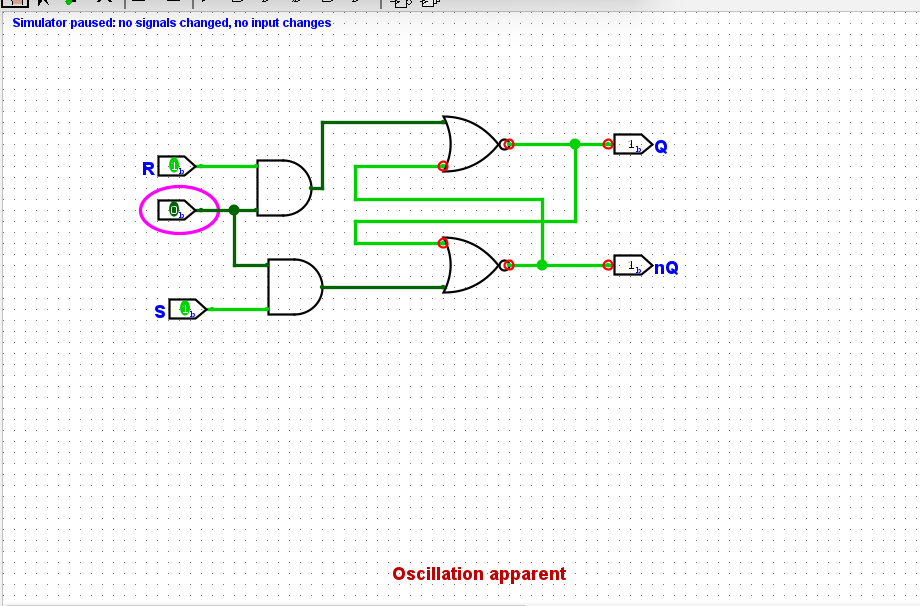
~S~R 锁存器
搭建如下:

行为如下:
- 当 R 为 0, S 为 1 时,上方与非门输出恒定为1,下方与非门输出恒为0. 此时Q为1, 故将SR锁存器存储的值更新为1。
- 当 R 为 1, S 为 0 时,下方与非门输出恒定为1,上方输出输出恒为0. 此时Q为0, 故将SR锁存器存储的值更新为0。
- 当 R 为 1, S 为 1 时,两个与非门的行为和反相器一致。此时锁存器的行为和交叉配对反相器一致, 故SR锁存器将保持之前存储的值。
- 当 R 为 0 ,S 为 0 时,两个门的输出均为1。并且从 sr 从 00 变为 11 时,锁存器进入震荡的亚稳态。
分析D锁存器的行为
通过分析 WE 是否使能开始:
- WE 使能,则 S = D, R = not D. 这种情况下如果D是1,那么Q为1; D是0的话, Q为0,也就是说 Q = D.
- WE 不使能,则S = 0,R = 0. 这种情况下,Q将保持。
就是说,S 和 R 同时为1的情况就不存在了。自然 11 到 00 的跳变也不会存在。
真值表如下:
| WE | D | Q |
|---|---|---|
| 0 | x | hold |
| 1 | 1 | 1 |
| 1 | 0 | 0 |
搭建D锁存器

带复位功能的D锁存器
这个reset是低电平有效的

用D锁存器实现位翻转功能
D = ~D, 在输入没有变化的时候,输出一直在反转,所以仿真程序认为出现了震荡。
D 触发器

带复位功能的D触发器
将主和子锁存器的Reset连接到Reset信号就可以了

D触发器实现位翻转功能
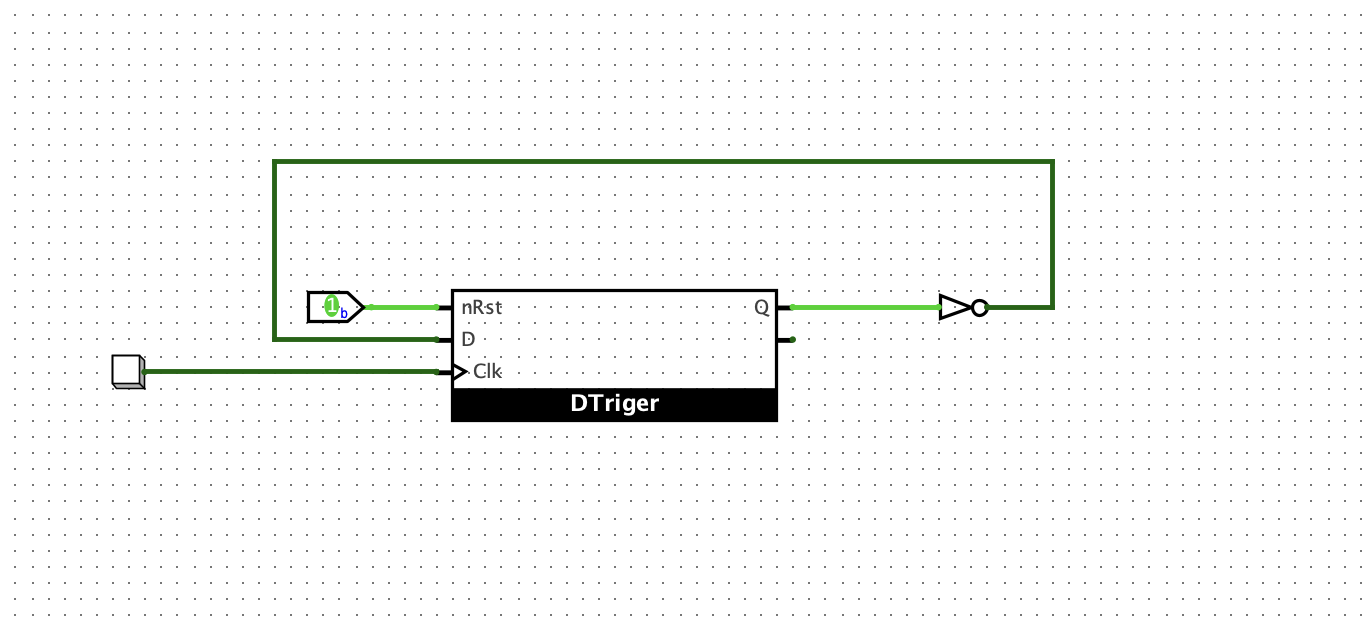
下降沿触发的D触发器
有下面两种方式:
- 主锁存器的CLK信号输入不取反,子锁存器的CLK信号取反
- 将上升沿的D触发器的CLK信号取反
搭建带使能端的D触发器
想法是对CLK进行一次 与 操作,就是当 EN 为0时,CLK的变化被忽略。

4位寄存器

验证如下: 输入的值不会马上生效,必须等到按一下button才会显示在数码管上。
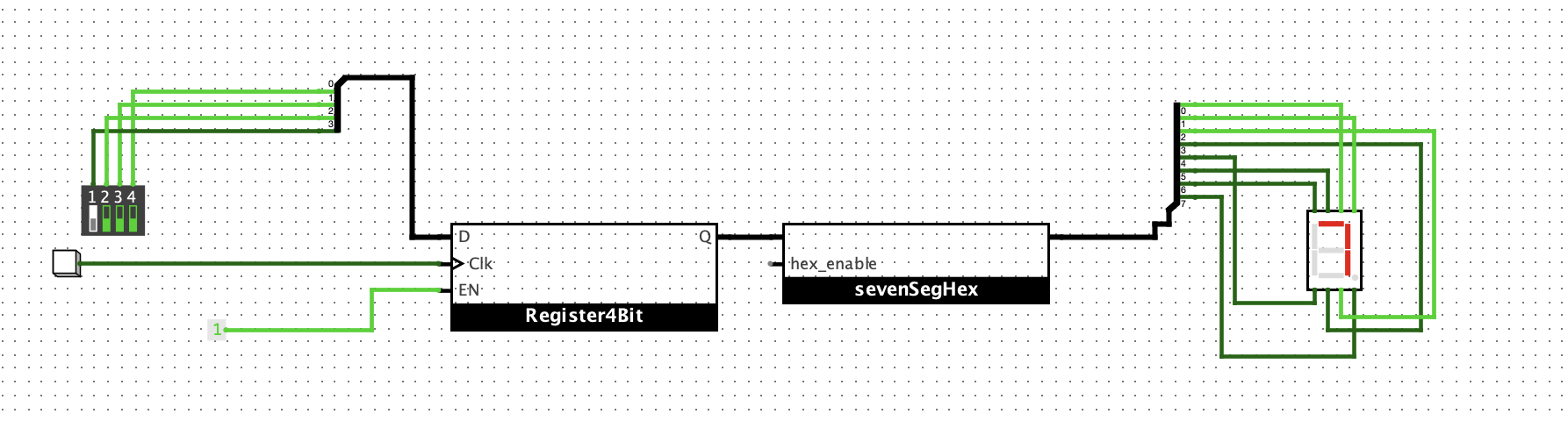
搭建4位计数器
想法是这样的: 每一个 clk 来的时候,v = v + 1。 也就是说,当clk来的时候,寄存器将上一次求和的值刷新到新的Q,然后把这个Q+1作为输入,等待下一次的时钟。
如下:

验证如下:
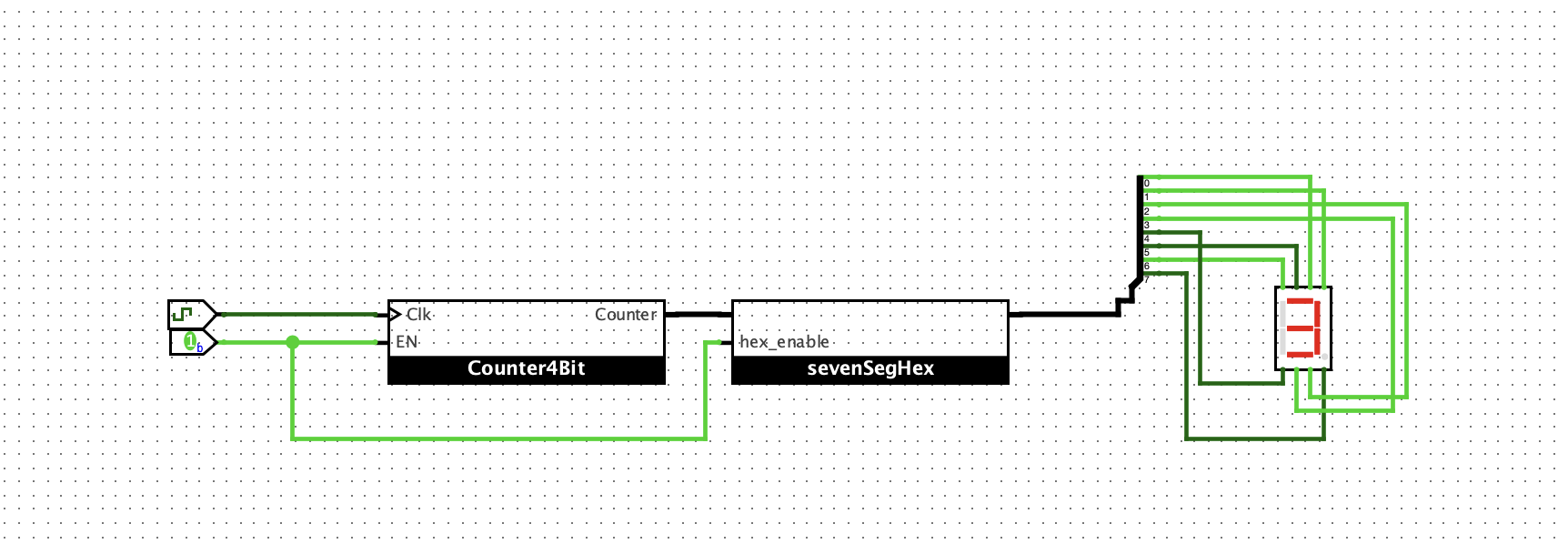
设计数列求和电路
先前设计的修改
- 发现先前设计的sr寄存器有概率仿真开始的时候就出现震荡,所以我在R加了一个 POR 信号。这样就稳定多了
- 扩展了8位寄存器和8位全加器
- 修正 DLatch, En信号不应该直接与 CLK 信号进行 &,应该与 非/和原始信号分别 &
设计如下:
- 加数从0开始递增,每一个clock递增1
- sum初始值为0,每一个clock与加数进行相加
- 时钟产生10个tick后,输出结果

验证如下: 输出 1+2+3+…+10 = 0x37
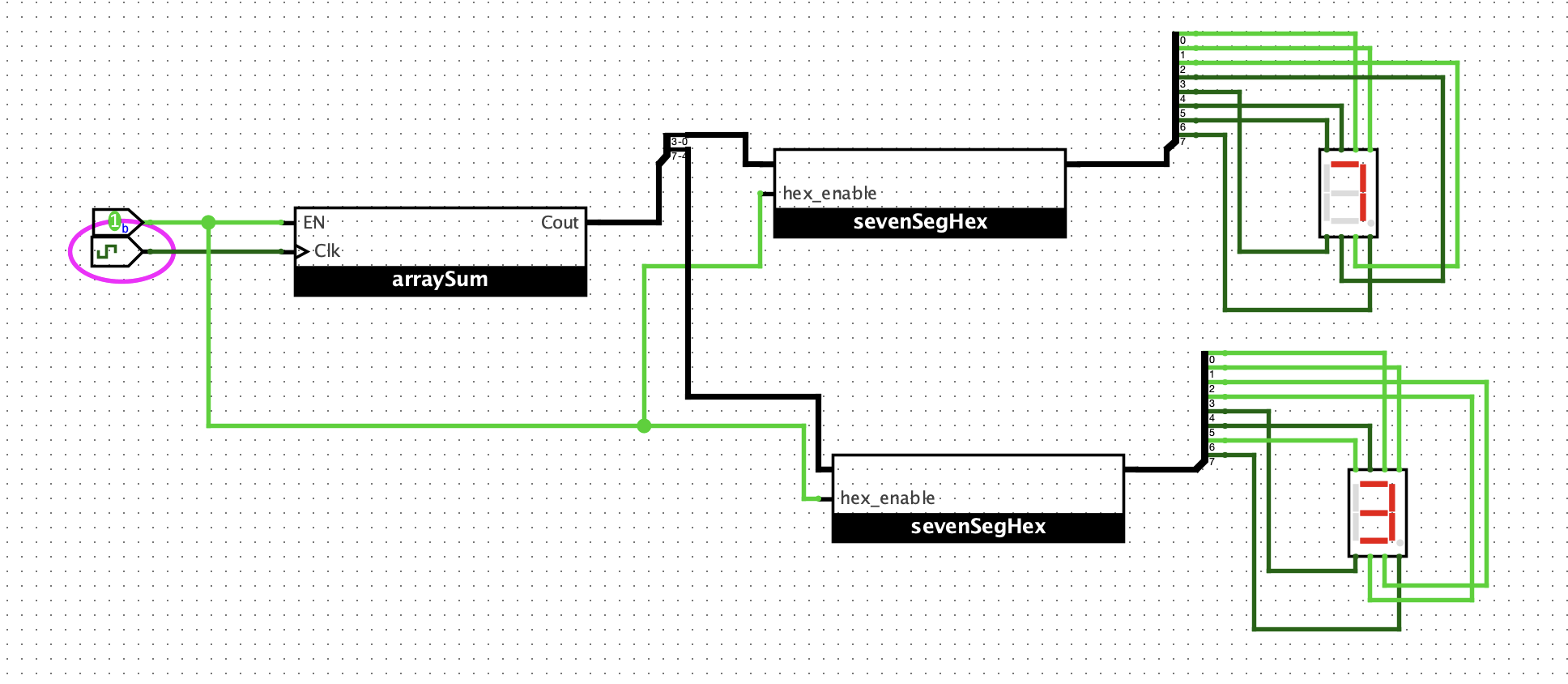
实现电子时钟
想法如下:
- 2个8位累加器 分别代表 秒和分
- 设计8位比较器
- 秒累加器的输出等与60时,产生一次分的clk,让分累加器 +1,然后将秒累加器的输出复位
- 分累加器的输出等与60时,将分累加器的输出复位
实现如下:

验证如下:
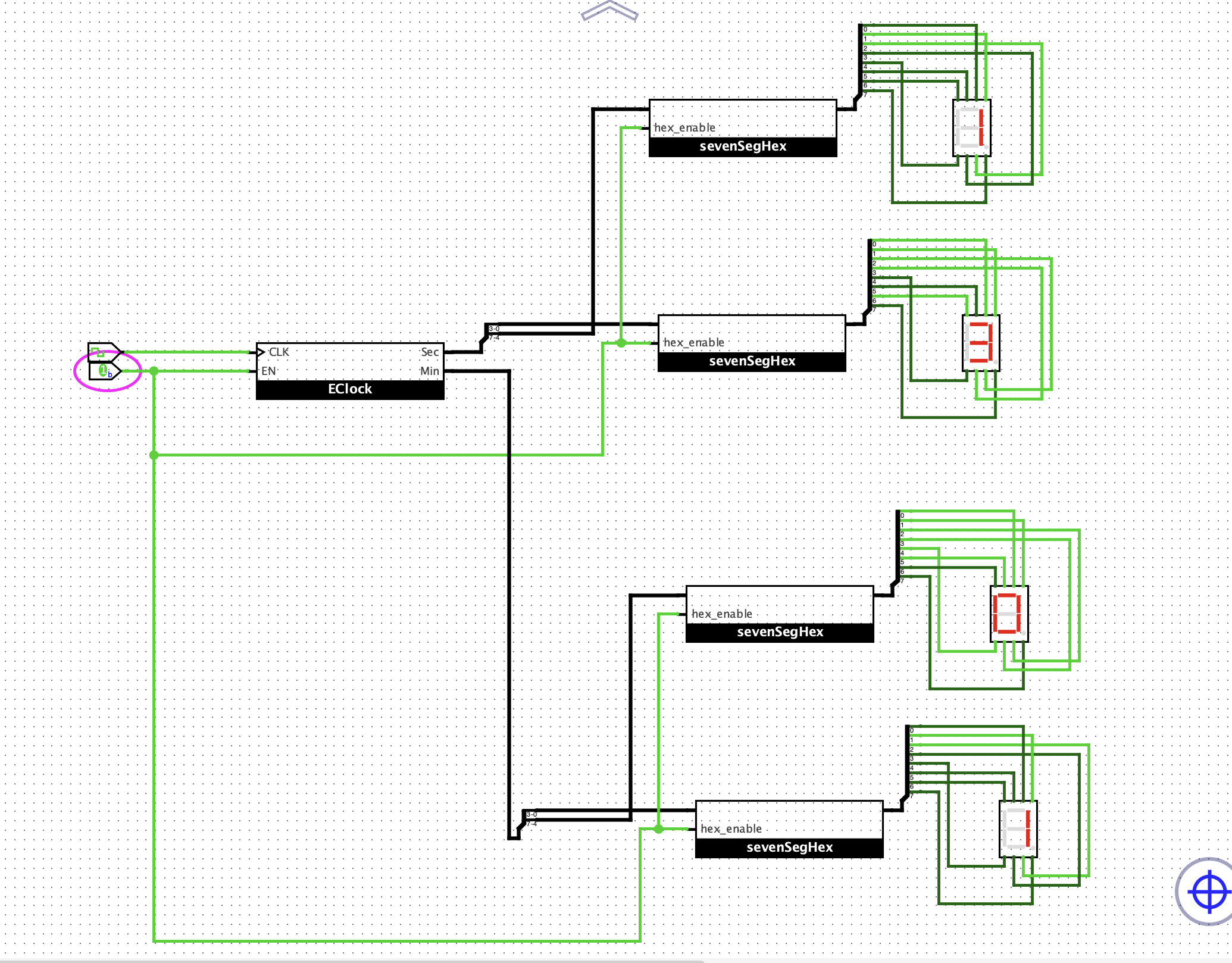
note: 为了方便,我这里没有做10分的显示,用了两个16进制的显示。
attention:
加了复位电路也没有办法完全解决震荡问题,我的版本如下:
Product: Logisim-evolution v4.1.0
Runs on: Java HotSpot(TM) 64-Bit Server VM v25.0.2
Compiled: 2026-02-15T09:21:41+0100
Build ID: main/632d66dc
Built on: Java HotSpot(TM) 64-Bit Server VM v25.0.2
问了ai,建议是使用内置的srlatch,我单步调试过,貌似目前每一步会吧Q或者~Q的状态置为不确定,然后反复进行计算。
用当前我的电路时,只会在摆电路的时候出现震荡,如果有的话,复位再重新仿真,就不会出现问题。
high performace network
tcpdump 研究
想研究下tcpdump,主要是以下几点:
- bpf/ebpf 程序加载过程
- 用户态程序与内核之间的数据流分析
- 给我的基于DPDK的用户态抓包程序进行修改
gemini 给的的意见
我先让ai给我生成一下调研的大概方向,这是它给出的。令我意外的是, dpdk竟然还支持了用户态的ebpf-runtime,这里可以作为额外增加的一点调研方向。
当然,这是一个非常专业和有深度的研究目标。tcpdump 的架构是网络分析的基石,而将其思想与 DPDK 结合,则是通向高性能用户态网络处理的关键。
下面我为您设计一份分步、可行的研究方案。
宏观架构概览:tcpdump 是如何工作的?
在深入细节之前,我们先建立一个心智模型。tcpdump 的工作流程可以简化为以下几个核心组件的协作:
用户接口 (CLI): 你输入的命令,如 tcpdump -i eth0 'tcp port 80'。
libpcap 库: 这是 tcpdump 的心脏和大脑。它负责:
解析过滤表达式: 将 'tcp port 80' 这种人类可读的字符串,编译成 BPF (Berkeley Packet Filter) 虚拟机能够理解的字节码。
设置抓包会话: 创建一个特殊的套接字 (AF_PACKET socket),并将其绑定到指定的网络接口 (eth0)。
加载过滤器: 将编译好的 BPF 字节码通过 setsockopt 系统调用附加到这个套接字上。
读取数据: 从内核为这个套接字准备的环形缓冲区 (Ring Buffer) 中高效地读取数据包。
内核:
AF_PACKET Socket: 提供一个原始接口,允许用户态程序直接访问链路层的数据包。
BPF 虚拟机 (JIT): 在内核中运行 libpcap 提供的 BPF 程序。当网络接口收到一个包后,数据会经过这个虚拟机。
过滤: 如果数据包不匹配 BPF 过滤器,内核会直接丢弃它,根本不会将其复制到用户态,这是性能优化的关键。
数据拷贝: 如果数据包匹配,内核才将其拷贝到 AF_PACKET socket 的共享内存环形缓冲区中。
tcpdump 主程序:
从 libpcap 提供的接口循环读取匹配的数据包。
解析包头(Ethernet, IP, TCP/UDP 等)。
按照用户指定的格式,将解析后的信息打印到标准输出。
可行的研究方案
我们将按照您的三个目标,分阶段进行研究,从理论到实践。
阶段一:深入理解 BPF 加载与内核交互 (目标 1 & 2)
这个阶段的目标是亲手验证上述模型的每一个环节。
1. 理论学习与工具准备
阅读文档:
man pcap-filter: 学习 tcpdump 过滤表达式的语法。这是 BPF 语言的前端。
man tcpdump: 重点关注 -d, -dd, -ddd 选项,它们可以让你看到 libpcap 编译出的 BPF 汇编指令。
工具:
tcpdump: 我们的主要研究对象。
strace: 系统调用追踪神器,用它来观察 tcpdump 和内核之间到底发生了什么。
2. 动手实践:解剖 BPF 加载过程
编译过滤器:
运行命令: tcpdump -i any -d 'tcp and port 80'
观察输出: 你会看到类似 BPF 汇编的指令,例如 ldh [12], jeq #0x800, ...。这证明了 libpcap 确实将字符串编译成了 BPF 程序。
你的任务: 理解这些指令的含义。ldh (load half-word) 是在加载以太网头中的协议类型字段,jeq (jump if equal) 是在判断协议是否为 IP (0x0800)。
追踪系统调用:
运行命令: sudo strace -e trace=socket,setsockopt,recvfrom,mmap tcpdump -i eth0 -c 1 'host 1.1.1.1'
观察输出,并寻找关键调用:
socket(AF_PACKET, SOCK_RAW, ...): 这就是在创建抓包用的原始套接字。
setsockopt(..., SOL_SOCKET, SO_ATTACH_FILTER, ...): 这就是 BPF 程序的加载点! strace 会显示一个结构体,其中包含了 BPF 指令的数量和指向指令数组的指针。
mmap(...): 这是 libpcap 现代版本中的关键优化。它将内核的环形缓冲区直接内存映射到 tcpdump 的进程空间,避免了每次 read() 都需要从内核空间向用户空间拷贝数据的开销。
recvfrom(...) 或 poll(...): tcpdump 等待内核通知有新数据包到达,并从映射的内存中直接读取。
3. 总结数据流
入向 (Ingress): NIC -> 内核协议栈 -> BPF 过滤器 (在 AF_PACKET socket 上运行) -> (如果匹配) -> 拷贝到 AF_PACKET 的环形缓冲区 -> tcpdump 通过 mmap 的内存区域直接读取。
核心: 过滤发生在内核态,且尽早发生,极大地减少了无用数据拷贝和上下文切换的开销。
阶段二:对比 tcpdump 模型与 DPDK 模型
在修改你的 DPDK 程序之前,必须深刻理解两者在哲学上的根本不同。
特性 tcpdump / libpcap 模型 DPDK (Data Plane Development Kit) 模型
控制平面 内核 (Kernel) 用户态 (Userspace)
驱动 内核标准驱动 用户态驱动 (PMD - Poll Mode Driver)
数据路径 内核旁路,但仍需内核调度和数据拷贝(或 mmap) 内核完全旁路 (Kernel Bypass)
包处理方式 中断驱动 + poll/select (阻塞等待) 轮询 (Polling),死循环检查网卡队列是否有包
CPU 使用 较低,只在有包到达时被唤醒 极高,通常会独占一个或多个 CPU 核心 100%
数据拷贝 至少一次从 NIC DMA 到内核内存,再到用户态(mmap 优化) 零拷贝 (Zero-Copy),网卡直接 DMA 到用户态分配的内存
易用性 非常高,一个 apt install 即可用 复杂,需要绑定网卡、配置大页内存、处理 NUMA
性能 数 Gbps,受限于上下文切换和内核处理 数十乃至上百 Gbps,只受限于内存带宽和 CPU 速度
结论: tcpdump 是请求内核帮忙过滤,而 DPDK 是**“踢开”内核,自己直接操作硬件**。
阶段三:为你的 DPDK 程序设计和实现过滤功能 (目标 3)
现在,你的目标是为你的 DPDK 程序增加类似 tcpdump 的强大过滤能力。DPDK 本身不提供类似 'tcp port 80' 这样的高级过滤语言。你有以下几种方案可以实现,从易到难:
方案 A: 硬编码或简单解析 (入门级)
在你的 DPDK 抓包循环中,直接用 C/Rust 代码检查包头。
c复制代码
// DPDK main loop
struct rte_mbuf *pkts[BURST_SIZE];
const uint16_t nb_rx = rte_eth_rx_burst(port_id, 0, pkts, BURST_SIZE);
for (int i = 0; i < nb_rx; i++) {
struct rte_ether_hdr *eth_hdr = rte_pktmbuf_mtod(pkts[i], struct rte_ether_hdr *);
if (eth_hdr->ether_type == rte_cpu_to_be_16(RTE_ETHER_TYPE_IPV4)) {
// Check IP header for protocol, source/dest IP...
// Check TCP header for source/dest port...
// 如果匹配,则处理;否则,rte_pktmbuf_free(pkts[i])
} else {
rte_pktmbuf_free(pkts[i]);
}
}
优点: 简单直接,无外部依赖。
缺点: 不灵活,每次修改过滤规则都需要重新编译。
方案 B: 利用硬件过滤卸载 (性能最佳)
许多现代网卡支持硬件过滤 (Flow Director, 5-tuple filter 等)。你可以通过 DPDK 的 rte_flow API 将过滤规则编程到网卡硬件中。
优点: 性能最高,不匹配的包根本不会被 DMA 到主机内存,不消耗 CPU。
缺点: 并非所有网卡都支持,rte_flow API 相对复杂,支持的规则有限。
方案 C: 重用 libpcap 的编译器 + 用户态 BPF 解释器 (最灵活和强大)
这是最接近 tcpdump 思想的方案,强烈推荐。
链接 libpcap: 在你的 DPDK 项目中,包含 pcap.h 并链接 -lpcap。你只使用它的编译功能,不使用它的抓包功能。
获取 BPF 字节码:
c复制代码
#include <pcap/pcap.h>
// 假设 filter_string 来自用户输入,如 "tcp port 80"
const char *filter_string = "tcp port 80";
struct bpf_program fp;
// 使用 pcap_compile_nopcap 获取 BPF 程序,它不需要一个活动的 pcap_t 句柄
// DLT_EN10MB 表示链路层是 Ethernet
if (pcap_compile_nopcap(SNAPLEN, DLT_EN10MB, &fp, filter_string, 1, PCAP_NETMASK_UNKNOWN) < 0) {
// 错误处理
}
// 现在 fp.bf_insns 里就是编译好的 BPF 字节码
在用户态运行 BPF: DPDK 自带一个 BPF 库,可以加载并执行 BPF 程序。
c复制代码
#include <rte_bpf.h>
// 创建 BPF 执行上下文
struct rte_bpf *bpf_ctx = rte_bpf_load(&fp);
pcap_freecode(&fp); // 释放 libpcap 分配的资源
// ... 在你的 DPDK 抓包循环中 ...
for (int i = 0; i < nb_rx; i++) {
// 从 mbuf 中获取数据包的指针和长度
void *pkt_data = rte_pktmbuf_mtod(pkts[i], void *);
uint32_t pkt_len = rte_pktmbuf_data_len(pkts[i]);
// 在用户态执行 BPF 过滤
if (rte_bpf_exec(bpf_ctx, pkt_data, pkt_len) > 0) {
// 包匹配!进行处理...
} else {
// 包不匹配,释放
rte_pktmbuf_free(pkts[i]);
}
}
rte_bpf_destroy(bpf_ctx);
总结与建议
先完成阶段一,用 strace 和 tcpdump -d 把 libpcap 和内核的交互流程摸得滚瓜烂熟。
深刻理解阶段二的对比表格,明确你的 DPDK 程序在生态位上的不同。
直接上手实现阶段三的方案 C。这是最能体现你学习成果的方案,它完美地将 libpcap 的易用前端与 DPDK 的高性能后端结合在了一起,让你的程序既强大又灵活。
祝你研究顺利!这是一个非常有价值的技术深潜。
嗯,还比较合理。所以先从 strace 开始吧。
看看在输入 tcpdump -i bond0 'port 8888' 这个命令之后,整个程序都干啥了。
strace tcpdump -i bond0 ‘port 8888’
这个日志会很多,节选了一些我认为关键的部分。然后加了一些注释,即我认为它在干什么。
//...
// 早期启动阶段,说明tcpdump依赖 libpcap 库
openat(AT_FDCWD, "/usr/lib64/libpcap.so.1", O_RDONLY|O_CLOEXEC) = 3
...
// 一个 raw socket,用于后续操作
socket(AF_PACKET, SOCK_RAW, htons(0 /* ETH_P_??? */)) = 4
ioctl(4, SIOCGIFINDEX, {ifr_name="lo", ifr_ifindex=1}) = 0
ioctl(4, SIOCGIFHWADDR, {ifr_name="bond0", ifr_hwaddr={sa_family=ARPHRD_ETHER, sa_data=50:79:73:0d:9b:ed}}) = 0
// 开启混杂模式
setsockopt(4, SOL_PACKET, PACKET_ADD_MEMBERSHIP, {mr_ifindex=if_nametoindex("bond0"), mr_type=PACKET_MR_PROMISC, mr_alen=0, mr_address=50:79:73:0d:9b:ed}, 16) = 0
// 准备ringbuf
setsockopt(4, SOL_PACKET, PACKET_AUXDATA, [1], 4) = 0
getsockopt(4, SOL_SOCKET, SO_BPF_EXTENSIONS, [64], [4]) = 0
mmap(NULL, 266240, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7faf62328000
getsockopt(4, SOL_PACKET, PACKET_HDRLEN, [48], [4]) = 0
setsockopt(4, SOL_PACKET, PACKET_VERSION, [2], 4) = 0
setsockopt(4, SOL_PACKET, PACKET_RESERVE, [4], 4) = 0
setsockopt(4, SOL_PACKET, PACKET_RX_RING, 0x7fff1856bb30, 28) = 0
mmap(NULL, 2097152, PROT_READ|PROT_WRITE, MAP_SHARED, 4, 0) = 0x7faf61a00000
// 开始attach filter
bind(4, {sa_family=AF_PACKET, sll_protocol=htons(ETH_P_ALL), sll_ifindex=if_nametoindex("bond0"), sll_hatype=ARPHRD_NETROM, sll_pkttype=PACKET_HOST, sll_halen=0}, 20) = 0
setsockopt(4, SOL_SOCKET, SO_ATTACH_FILTER, {len=24, filter=0x55ea646ae0d0}, 16) = 0
datapath优化
可以看到,tcpdump抓包是用了 packet mmap 的方法。 主要是这么几步:
[setup] socket() -------> creation of the capture socket
setsockopt() ---> allocation of the circular buffer (ring)
option: PACKET_RX_RING
mmap() ---------> mapping of the allocated buffer to the
user process
[capture] poll() ---------> to wait for incoming packets
[shutdown] close() --------> destruction of the capture socket and
deallocation of all associated
resources.
它比直接读写fd,就是少了一次从内核态到用户态的数据拷贝。感觉这里带来的性能提升应该还是很可观的。 不知道 rust 的标准库是不是采用的这个方法?我觉得应该不是,不然的话标准库可能得实现一套完整的协议栈了。 这里留个坑,我觉得可以做下这两种情况下的性能对比。
libpcap 生成过滤条件
由于 libpcap 是用户态的,strace 现在还不能看具体是干了什么。不过我知道好像 ftrace 可以?
anyway, 先尝试看看源码和文档,看看 libpcap 对于这种 ‘port 8888’ 具体会生成什么东西。
bpf 分析
[root@localhost ~]# tcpdump -i bond0 -d "port 8888"
(000) ldh [12]
(001) jeq #0x86dd jt 2 jf 10
(002) ldb [20]
(003) jeq #0x84 jt 6 jf 4
(004) jeq #0x6 jt 6 jf 5
(005) jeq #0x11 jt 6 jf 23
(006) ldh [54]
(007) jeq #0x22b8 jt 22 jf 8
(008) ldh [56]
(009) jeq #0x22b8 jt 22 jf 23
(010) jeq #0x800 jt 11 jf 23
(011) ldb [23]
(012) jeq #0x84 jt 15 jf 13
(013) jeq #0x6 jt 15 jf 14
(014) jeq #0x11 jt 15 jf 23
(015) ldh [20]
(016) jset #0x1fff jt 23 jf 17
(017) ldxb 4*([14]&0xf)
(018) ldh [x + 14]
(019) jeq #0x22b8 jt 22 jf 20
(020) ldh [x + 16]
(021) jeq #0x22b8 jt 22 jf 23
(022) ret #262144
(023) ret #0
指令本身还是很好理解的,但是类似于 [12],这种指向的是哪儿呢?可能还需要去看看BPF调用规范。
- BPF engine and instruction set
btw,我之前做过nes的simulator,所以对这三个参数倍感亲切,
-
首先描述寄存器
bpf不像epbf,寄存器很简单,只有一个32位的 A(累加) 寄存器,一个32位的 X 寄存器,16个32位的M[i]寄存器
-
指令 (linux/filter.h以及 linux/bpf_common.h )
就不搬了,常见的 load/store/je/jne, 对于算数有 add/sub/mul/div/neg/mod/xor 等 filter.h 中还定义了额外的一些linux上的扩展,用于获取 socket buffer 的额外信息等。
-
address mode
一共有 12 种,之前疑惑的 [k] 这样的是mode 4,代表
BHW at byte offset k in the packet。 看看其它访问内存的mode,都是以数据包的地址作为基础地址。这么说起来 cBPF 只是为了抓包而生的,因为别的内存它都访问不到。返回支持返回立即数和A寄存器。
参考kernel文档
-
host 8888bpf code分析现在分析这个就很直观了,伪代码大致如下:
int filter(char *pkt) { if (((u16*)ptr)[12/2] == 0x86dd) { // ipv6 case if (ptr[20] == 0x11||ptr[20] == 0x6 || ptr[20] == 0x84) { // tcp, udp or stcp u16 sport = *(u16*)&ptr[54]; u16 dport = *(u16*)&ptr[56]; if (sport == 8888 || dport == 8888) { return 262144; } } } else if (((u16*)ptr)[12/2] == 0x0800) { // ipv4 if (ptr[23] == 0x11||ptr[23] == 0x6 || ptr[23] == 0x84) { if (*(u16*)&ptr[20]&0x1fff == 0) { // fragment offset == 0 u8 hdr_len = ptr[14]*0xf * 4; u16 sport = *(u16*)&ptr[14+hdr_len]; u16 dport = *(u16*)&ptr[14+hdr_len]; if (sport == 8888 || dport == 8888) { return 262144; } } } } return 0 }
kernel bpf attach
setsockopt(4, SOL_SOCKET, SO_ATTACH_FILTER, {len=24, filter=0x55ea646ae0d0}, 16) = 0
这里,应该就是把上面的BPF code attach到kernel。不过内核似乎不是真正的接受这种 BPF 码。 它接受了一个结构体,描述了这些码的格式。
struct sock_filter { /* Filter block */
__u16 code; /* Actual filter code */
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
struct sock_fprog { /* Required for SO_ATTACH_FILTER. */
unsigned short len; /* Number of filter blocks */
struct sock_filter __user *filter;
};
{len=24, filter=0x55ea646ae0d0} 看这个参数,说明tcpdump传递给内核的一共是 24 个 sock_filter{}
其中的内容也可以和我们上面的分析对应:一共24条指令,一条指令对应一个结构体。
socket—fd 已经有 网卡的各种信息,那么具体的这个filter是被attach到什么点呢?以及kernel是怎么运行这个code的? 希望能够继续深入研究一下。
-
SO_ATTACH_FILTER attach point
这里除了看代码似乎没有什么别的好办法,大概画个流程图吧。
整个流程最主要的是将用户态传入的程序进行检查,然后选择一个jit runtime进行运行。 最终把socket的sk_filter置为jit code。
而这个socket又是什么呢?在 net/socket.c 中可以看到,是 socket 这种fd的 privdata。在sys_socket系统调用时被创建。 具体的来说,通过 __sock_create 创建。
通过strace可以看出前面tcpdump创建的net_family为AF_PACKET,由此我们找到对应的create函数为 net / packet / af_packet.c :: packet_create
create 动作比较复杂,不过我觉得主要关心
po->prot_hook.func = packet_rcv这一行就可以。不对,set tx/rx ring的方法会把这个callback改为 tpacket_rcv,或许这才是我们要关注的。
setsockopt(syscall) -> __sys_setsockopt -> do_sock_setsockopt -> sock_setsockopt -> sk_setsockopt
-> sk_attach_filter -> __get_filter (jit happened)
-> __sk_attach_prog
-
callback point: tpacket_rcv
tpacket_rcv 调用 run_filter, 最终一路调用到run bpf code。获取完res值之后,如果res > 0,就说明这个包需要拷贝。
这里调用了skb_copy_bit(),把 skb 的数据拷贝到了ringbuf中,然后把status置上 TP_STATUS_USER 。这样,用户态就能访问到数据了。
那么这个tpacket_rcv会在哪里被调用呢?答案在 dev_add_pack, 对于 AF_PACKET/PF_PACKET,会在这种类型下注册一下这个packet_type
由此当 __netif_receive_skb_core 收到包时,首先进行 do_xdp_generic(通用xdp抓包点,也就是软件模拟的xdp), 也就是这种dev的packet type 进行 deliver_skb
list_for_each_entry_rcu(ptype, &dev_net_rcu(skb->dev)->ptype_all, list) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } /// 这后面是 tc 点,所以也就是说 tcpdump 的挂载点是在 tc点之前的。 static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev) { if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC))) return -ENOMEM; refcount_inc(&skb->users); return pt_prev->func(skb, skb->dev, pt_prev, orig_dev); } -
*** 对于内核函数,这种回调常常会让人觉得找不到callstack,我们可以利用 eBpf机制 来轻松的得到调用栈。 ***
对于这次情况,就可以通过 bpftrace -e 'kprobe:tpacket_rcv { print(kstack); }' 来得出调用栈帧:
[root@localhost ~]# bpftrace -e 'kprobe:tpacket_rcv { print(kstack); }'
Attaching 1 probe...
tpacket_rcv+1
__netif_receive_skb_core+1800
__netif_receive_skb_list_core+319
__netif_receive_skb_list+251
netif_receive_skb_list_internal+254
napi_complete_done+111
igb_poll+99
__napi_poll+39
net_rx_action+563
__do_softirq+198
__irq_exit_rcu+161
common_interrupt+67
asm_common_interrupt+34
# 另外启动一个shell,运行tcpdump,正常这个函数不会被调用。
- kernel jit compiler 从 __get_filter 开始,一路调用到 bpf_jit_compile,这个后面有需要再深入研究吧。
dpdk ebpf support
源代码位于 app/test/test_bpf.c 中,描述了一组 ebpf 测例。
实现代码大部分位于 lib/librte_bpf 下面,目前支持了两种模式,jit 和 interpreter。
但是这个代码目前看起来只是实现了执行的部分,更具体的,比如说想要把这个程序attach到某个netdev,以及ebpf map,似乎没有很好的支持。
我觉得这个可能更多的是做一些抓包工具,可能稍微修改一下就能使得现在的 tcpdump 工作在dpdk上。
文档也比较简陋,在后面看看是否能够作一些相关的有趣的事情。
lldp-tool
LLDP 是一种链路层协议,可以发现链路上的其它设备(需要其他设备同时开启)。
centos上安装lldp
yum install lldpd -y
systemctl start lldpd.service
查看 neighbour 信息
[root@localhost ~]# lldpcli show neighbors
-------------------------------------------------------------------------------
Interface: ens2f1np1, via: LLDP, RID: 2, Time: 0 day, 00:25:58
Chassis:
ChassisID: mac 90:74:2e:f0:a0:6e
SysName: xxxx
SysDescr: H3C Comware Platform Software, Software Version 7.1.070, Release 8307P10
H3C S6850-56HF-G
Copyright (c) 2004-2024 New H3C Technologies Co., Ltd. All rights reserved.
MgmtIP: 10.254.55.220
Capability: Bridge, on
Capability: Router, on
Port:
PortID: ifname HundredGigE1/0/49
PortDescr: HundredGigE1/0/49 Interface
TTL: 121
-------------------------------------------------------------------------------
ebpf gateway
some link:
业务场景
基于 epbf 技术做一个网关,这个网关主要处理 VPC 之间,以及VPC到经典网络之间的流量。
业务逻辑设计
- 三层转发,不需要 MAC 信息
- 基于路由的转发逻辑,VPC 内支持
- 策略路由(from xxx lookup table xxx),
- 自定义路由(ip r add xxx table xxx),
- 系统路由(ip route add xxx table main)
- VPC 内的VMNC信息,是 /32 or /128位的精准系统路由
- EIP 支持,1:1的公网ip
- NAT 支持,从 VPC网络 到 经典网络的转发支持
- 可观测性/可调试性
开发过程
- 控制面:
- 自然的接入k8s/restApi,
- 提供数据面热加载能力
- naive 读写 BPF map 能力支持
- 数据面
- 实现业务逻辑
- 挂载在 xdp 点: 可能有加速,就算没有加速,内核也有generic xdp可以使用。
结合团队开发情况,使用 Go + c 来开发。
数据面开发
-
maps design
- route table: LpmTrieMap
- key: vpcId + TableId + addr
- value: route action
- eip table(and reverse table): hashMap
- key: vpcId + Ip
- value: eip
- ct table: ringbuf?
- key: tuple(src,dst,srcport,dstport,proto)
- value: ct action
- sa pool table: ringbufMap
- key: none
- value: addr+port
- global ip: array
- key: index
- value: vip
- route table: LpmTrieMap
-
dp design
xdp ======= is_geneve ===y===> tunnel_process =====> nat_process: sa_pool fetch && ct create || ct reuse
|| || (in vpc)
|| ===============> Re-encap
|| ||
========> ct_lookup ==>
||
=======> to kernel
控制面开发
-
restApi compat, event driven
- eBpf maps write/read
- announce and revoke bgp
-
reload dp on startup (对于我们这种场景,不需要像cilium一样热编译代码)
cilium
学习一下cilium。
dpdk router
RRDMA
实现一个自己的 RDMA 虚拟网卡,纯软件模拟,基于 Rust 开发。类似 soft-roce,让普通以太网卡支持 RDMA/RoCE 协议。
技术选型
| 方案 | 选择 | 理由 |
|---|---|---|
| io_uring 用户态 | ✅ | 开发效率高、调试容易、生态成熟 |
| Rust 内核模块 | ⏸️ 待研究 | 研究价值高,但开发周期长 |
阶段一:Rust io_uring 基础操作
目标
掌握 io_uring 的基本使用,能够进行异步 I/O 操作。
学习路线
1. io_uring 概念入门
└── 理解 SQ (Submit Queue) 和 CQ (Completion Queue)
└── 理解 SQE (Submission Queue Entry) 和 CQE (Completion Queue Entry)
2. 基础 API 使用
├── 使用 io-uring crate 进行文件读写
├── 使用 tokio-uring 进行异步编程
└── 理解 registered buffers 和 fixed files
3. 网络 I/O
├── UDP socket 收发
└── 多队列和批量操作
参考资源
官方文档和教程
| 资源 | 链接 | 说明 |
|---|---|---|
| io-uring crate | https://docs.rs/io-uring/latest/io_uring/ | Rust io_uring 的官方 crate |
| tokio-uring | https://docs.rs/tokio-uring/latest/tokio_uring/ | Tokio 集成 io_uring |
| io_uring 官方文档 | https://unixism.net/2020/04/io-uring-by-example-1-introduction-to-io_uring/ | 完整的 io_uring 教程系列 |
开源示例
| 资源 | 链接 | 说明 |
|---|---|---|
| uring_examples | https://github.com/espoal/uring_examples | Rust io_uring 示例集 |
| uring-fs | https://docs.rs/uring-fs/latest/ | 异步文件系统操作 |
| tokio-uring 博客 | http://developerlife.com/2024/05/25/tokio-uring-exploration-rust/ | 详细的中文教程 |
关键概念
1. 提交队列 (Submit Queue)
- 应用提交 I/O 请求的地方
- SQE 包含操作类型、缓冲区指针、用户数据等
2. 完成队列 (Completion Queue)
- 内核返回 I/O 完成状态的地方
- CQE 包含结果状态、用户数据等
3. Registered Buffers
- 预先注册内存到内核,避免每次 I/O 拷贝
- 零拷贝发送的关键
4. Fixed Files
- 预先注册文件描述符,减少系统调用开销
实践任务
| 序号 | 任务 | 验收标准 |
|---|---|---|
| 1.1 | 安装 liburing 开发库 | apt install liburing-dev 成功 |
| 1.2 | 编译运行 io-uring 示例 | 文件读取成功 |
| 1.3 | 使用 tokio-uring 重写 | 异步读取文件 |
| 1.4 | UDP echo server | 能收发 UDP 包 |
| 1.5 | 使用 registered buffers | 实现零拷贝发送 |
阶段一检查点
- 理解 io_uring 的工作原理
- 能用 io-uring crate 进行文件读写
- 能用 tokio-uring 进行异步编程
- 能用 UDP socket 收发数据
- 理解 registered buffers 的使用场景
阶段二:基于 Rust 的 RoCEv2 协议实现
目标
实现完整的 RoCEv2 协议栈,包括 IB 传输层、UDP/IP 封装、以太网帧。
RoCEv2 协议栈结构
┌─────────────────────────────────────────────────────────────┐
│ 应用层 (Verbs) │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ IB 传输层 (L4) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ BTH │ │ RETH │ │ AETH │ │ DETH │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ - opcode │ - va │ - syndrome│ - q_key │ │
│ - dest_qp │ - rkey │ - msn │ - src_qp │ │
│ - psn │ - length │ │ │ │
│ - ack_req │ │ │ │ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ UDP 层 (L3) │
│ - Source Port: 散列算法计算 (entropy) │
│ - Dest Port: 4791 (RoCEv2 标准端口) │
│ - Checksum: RoCEv2 必须为 0 │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ IP 层 (L3) │
│ - IPv4 或 IPv6 │
│ - TTL/Hop Limit │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 以太网层 (L2) │
│ - EtherType: 0x8915 (RoCE) │
│ - MAC 地址 │
└─────────────────────────────────────────────────────────────┘
参考资源
协议规范
| 资源 | 链接 | 说明 |
|---|---|---|
| IB Spec Annex A17 RoCEv2 | https://www.scribd.com/document/350043431/Annex17-RoCEv2 | 官方 RoCEv2 规范 |
| RoCEv2 Protocol 详解 | https://qsysarch.com/posts/the-infiniband-transport-protocol-of-rocev2/ | IB 传输层详解 |
| Nvidia RoCEv2 文档 | https://docs.nvidia.com/networking/display/winofv55053000/rocev2 | 厂商实现文档 |
| Broadcom RoCEv2 CNP | https://docs.broadcom.com/doc/NCC-WP1XX | 拥塞控制说明 |
| Netdev RoCEv2 介绍 | https://netdevconf.org/0x19/docs/netdev-0x19-paper18-talk-slides/netdev-0x19-AI-networking-RoCE-and-netdev.pdf | 协议概览 |
协议头部格式
BTH (Base Transport Header) - 12 bytes
| 字段 | 位数 | 说明 |
|---|---|---|
| Opcode | 8 | 操作码 (Send/Recv/RDMA Write/RDMA Read) |
| Solicited Event | 1 | 是否请求事件 |
| Mig Req | 1 | 迁移请求 |
| Pad Count | 3 | 填充字节数 |
| Transport Version | 3 | 传输版本 |
| P_Key | 16 | 分区密钥 |
| Reserved | 8 | 保留 |
| Dest QP | 24 | 目标队列对编号 |
| Ack Req | 1 | 请求确认 |
| PSN | 24 | 包序列号 |
AETH (Ack Extended Transport Header) - 4 bytes
| 字段 | 位数 | 说明 |
|---|---|---|
| Syndrome | 8 | 0=ACK, 1=NACK, 3=RNR NACK |
| MSN | 24 | 消息序列号 |
RETH (RDMA Extended Transport Header) - 16 bytes)
| 字段 | 位数 | 说明 |
|---|---|---|
| Virtual Address | 64 | 远程虚拟地址 |
| Remote Key | 32 | 远程访问密钥 |
| Length | 32 | 数据长度 |
UDP 封装规则
- 目的端口: 4791 (标准 RoCEv2 端口)
- 源端口:
(SrcPort XOR DstPort) OR 0xC000计算 - 校验和: 必须设置为 0 (RoCEv2 要求)
开源参考实现
| 资源 | 链接 | 说明 |
|---|---|---|
| Alex Forencich UDP/IP Stack | https://github.com/alexforencich/verilog-ethernet | FPGA 实现的以太网栈,包含 RoCEv2 参考 |
| RoCEv2 FPGA Parser | https://www.mdpi.com/2079-9292/13/20/4107 | 学术论文中的 RoCEv2 实现 |
| soft-roce 源码 | https://github.com/SoftRoCE/rxe-rdma-kernel | C 实现的 RDMA 软件模拟 |
实践任务
| 序号 | 任务 | 验收标准 |
|---|---|---|
| 2.1 | 实现 BTH 头部 | 序列化/反序列化正确 |
| 2.2 | 实现 AETH 头部 | ACK/NACK 构造正确 |
| 2.3 | 实现 RETH 头部 | RDMA Read/Write 支持 |
| 2.4 | 实现 UDP 封装 | UDP 端口 4791,校验和为 0 |
| 2.5 | 实现 IP 封装 | IPv4 头部构造正确 |
| 2.6 | 实现以太网帧 | EtherType 0x8915 |
| 2.7 | 完整报文构造 | Wireshark 能解析 |
阶段二检查点
- 理解 RoCEv2 协议栈各层
- 能正确构造 BTH/AETH/RETH 头部
- 能构造完整的 RoCEv2 报文
- Wireshark 能正确识别报文格式
- 实现 UDP 校验和为 0 的规则
阶段三:ibverbs API 实现
目标
实现完整的 RDMA Verbs API,包括 Protection Domain、Memory Region、Completion Queue、Queue Pair 等核心概念。
RDMA 核心概念
┌─────────────────────────────────────────────────────────────────┐
│ RDMA 资源层次结构 │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Context (设备上下文) │ │
│ │ - 代表一个 RDMA 设备 │ │
│ │ - 管理所有资源的生命周期 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────────────────┐ ┌───────────────┐ ┌─────────────────┐ │
│ │ Protection │ │ Completion │ │ QP │ │
│ │ Domain (PD) │ │ Queue (CQ) │ │ (Queue Pair) │ │
│ │ │ │ │ │ │ │
│ │ - 内存隔离 │ │ - 异步通知 │ │ - SQ (发送) │ │
│ │ - 访问控制 │ │ - 完成事件 │ │ - RQ (接收) │ │
│ └─────────────────┘ └───────────────┘ └─────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Memory Region │ │
│ │ (MR) │ │
│ │ │ │
│ │ - lkey (本地) │ │
│ │ - rkey (远程) │ │
│ │ - VA (虚拟地址) │ │
│ │ - Length │ │
│ └─────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
QP 状态机
┌─────────────────────────────────────────────────────────────┐
│ QP 状态机 │
│ │
│ RESET ──────► INIT ──────► RTR ──────► RTS │
│ │ │ │ │ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ ERROR ERROR ERROR ERROR │
│ │ │
│ ▼ │
│ CLOSING │
│ │ │
│ ▼ │
│ ERROR │
└─────────────────────────────────────────────────────────────┘
状态说明:
- RESET: 初始状态,QP 不可用
- INIT: 已初始化,可以接收 RTR 请求
- RTR (Ready to Receive): 可以接收数据
- RTS (Ready to Send): 可以发送数据
参考资源
Rust ibverbs 库
| 资源 | 链接 | 说明 |
|---|---|---|
| rust-ibverbs | https://github.com/jonhoo/rust-ibverbs | 最流行的 Rust ibverbs 绑定 (197 ⭐) |
| safeverbs | https://github.com/crazyboycjr/safeverbs | 内存安全的 RDMA API (1 ⭐) |
| rdma-rs | https://github.com/phoenix-dataplane/rdma-rs | Rust RDMA 包装器 (2 ⭐) |
| rdma-sys | https://github.com/datenlord/rdma-sys | RDMA FFI 绑定 (49 ⭐) |
| async-rdma | https://github.com/datenlord/async-rdma | 异步 RDMA 框架 (163 ⭐) |
| rdma-cm | https://github.com/akshayknarayan/rdma-cm | RDMA CM 绑定 (1 ⭐) |
ibverbs 官方文档
| 资源 | 链接 | 说明 |
|---|---|---|
| ibverbs crate docs | https://docs.rs/crate/ibverbs/latest | Rust 绑定文档 |
| IB Spec Verbs | https://www.infiniband.org/specs/ | 官方 IB 规范第 11 章 |
| RDMAmojo | https://www.rdmamojo.com/ | RDMA 教程网站 |
核心 API
Protection Domain (PD)
// C API
struct ibv_pd *ibv_alloc_pd(struct ibv_context *context);
int ibv_dealloc_pd(struct ibv_pd *pd);
Memory Region (MR)
// C API
struct ibv_mr *ibv_reg_mr(struct ibv_pd *pd, void *addr, size_t length,
int access);
int ibv_dereg_mr(struct ibv_mr *mr);
Completion Queue (CQ)
// C API
struct ibv_cq *ibv_create_cq(struct ibv_context *context, int cqe,
void *cq_context, struct ibv_comp_channel *channel,
int comp_vector);
int ibv_destroy_cq(struct ibv_cq *cq);
int ibv_poll_cq(struct ibv_cq *cq, int num, struct ibv_wc *wc);
int ibv_req_notify_cq(struct ibv_cq *cq, int solicited_only);
Queue Pair (QP)
// C API
struct ibv_qp *ibv_create_qp(struct ibv_pd *pd, struct ibv_qp_init_attr *attr);
int ibv_destroy_qp(struct ibv_qp *qp);
int ibv_modify_qp(struct ibv_qp *qp, struct ibv_qp_attr *attr,
int attr_mask);
Work Request (WR)
// C API
int ibv_post_send(struct ibv_qp *qp, struct ibv_send_wr *wr,
struct ibv_send_wr **bad_wr);
int ibv_post_recv(struct ibv_qp *qp, struct ibv_recv_wr *wr,
struct ibv_recv_wr **bad_wr);
参考项目结构
erdmaverbs/
├── Cargo.toml
├── src/
│ ├── lib.rs # 库入口
│ ├── context.rs # Device Context
│ ├── pd.rs # Protection Domain
│ ├── mr.rs # Memory Region
│ ├── cq.rs # Completion Queue
│ ├── qp.rs # Queue Pair
│ ├── wr.rs # Work Request
│ ├── wc.rs # Work Completion
│ └── ffi/ # FFI 绑定
│ └── mod.rs
├── build.rs # 绑定生成
└── tests/
└── basic_test.rs
实践任务
| 序号 | 任务 | 验收标准 |
|---|---|---|
| 3.1 | 实现 Context | 能打开/关闭设备 |
| 3.2 | 实现 PD | 能分配/释放保护域 |
| 3.3 | 实现 MR | 能注册内存,返回 lkey/rkey |
| 3.4 | 实现 CQ | 能创建/销毁完成队列 |
| 3.5 | 实现 QP | 能创建 QP,实现状态机转换 |
| 3.6 | 实现 WR | 能发送 Send/Recv WR |
| 3.7 | 实现 WC | 能 poll 到正确的完成事件 |
阶段三检查点
- 理解 RDMA 核心概念 (PD/MR/CQ/QP)
- 能实现完整的 Verbs API
- QP 状态机转换正确
- 内存注册返回正确的 lkey/rkey
- 完成事件能正确通知应用
附录
技术栈总结
| 层级 | 技术/工具 | 用途 |
|---|---|---|
| I/O | io-uring / tokio-uring | 高性能异步 I/O |
| 网络 | UDP Socket | RoCEv2 报文收发 |
| FFI | bindgen | C 库绑定生成 |
| 协议 | 手写 RoCEv2 | IB over UDP |
| 测试 | Wireshark | 报文分析 |
推荐学习路径
第 1-2 周: io_uring 基础
│
├── 官方文档阅读
├── 编译运行示例代码
└── 实现 UDP echo server
│
└── 阶段一检查点 ✓
第 3-5 周: RoCEv2 协议
│
├── 阅读 IB Spec RoCEv2 章节
├── 实现 BTH/AETH/RETH 头部
├── 构造完整报文
└── Wireshark 验证
│
└── 阶段二检查点 ✓
第 6-10 周: ibverbs API
│
├── 阅读 rust-ibverbs 源码
├── 实现 PD/MR/CQ
├── 实现 QP 状态机
├── 实现 WR/WC
└── 集成测试
│
└── 阶段三检查点 ✓
参考资料汇总
io_uring
- https://docs.rs/io-uring/latest/io_uring/
- https://docs.rs/tokio-uring/latest/tokio_uring/
- https://github.com/espoal/uring_examples
- https://unixism.net/2020/04/io-uring-by-example-1-introduction-to-io_uring/
RoCEv2 协议
- https://www.scribd.com/document/350043431/Annex17-RoCEv2
- https://qsysarch.com/posts/the-infiniband-transport-protocol-of-rocev2/
- https://docs.nvidia.com/networking/display/winofv55053000/rocev2
- https://github.com/alexforencich/verilog-ethernet
ibverbs
- https://github.com/jonhoo/rust-ibverbs
- https://docs.rs/crate/ibverbs/latest
- https://www.rdmamojo.com/
- https://github.com/datenlord/async-rdma
环境安装
# 安装编译依赖
sudo apt install -y \
build-essential \
libclang-dev \
libnuma-dev \
librdmacm-dev \
libibverbs-dev \
liburing-dev
# 安装 Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
# 验证安装
cargo --version
rustc --version
方案二:Rust 内核模块实现 (待研究)
启动条件
- io_uring 方案完成基础功能后
- 或有充足时间 (6+ 个月)
- 或有明确的学术研究目标
参考项目
待研究内容
- Rust 内核编程约束
- 内存安全与内核兼容性
- 调试与错误排查
RDMA libibverbs 初始化与数据路径指南
*** 这个是AI 生成的参考文档,不一定正确!!! ***
📖 目录
RDMA 初始化流程
初始化步骤概览
┌─────────────────────────────────────────────────────────────┐
│ RDMA 初始化流程 │
└─────────────────────────────────────────────────────────────┘
Step 1: 获取 RDMA 设备
↓
Step 2: 打开设备并获取上下文
↓
Step 3: 查询设备属性
↓
Step 4: 分配保护域(PD)
↓
Step 5: 创建完成队列(CQ)
↓
Step 6: 创建队列对(QP)
↓
Step 7: 注册内存区域(MR)
↓
Step 8: 建立连接(可选)
↓
✅ 初始化完成,可以开始数据传输
详细初始化步骤
Step 1: 获取 RDMA 设备列表
┌──────────────────────────────────┐
│ ibv_get_device_list() │
│ 获取系统中所有 RDMA 设备 │
└──────────────────────────────────┘
↓
返回设备列表
├─ device[0]: mlx5_0
├─ device[1]: mlx5_1
└─ device[2]: NULL (列表结束)
关键信息:
- 返回
struct ibv_device **指针数组 - 最后一个元素为 NULL
- 需要手动释放:
ibv_free_device_list()
Step 2: 打开设备并获取上下文
┌──────────────────────────────────────────┐
│ ibv_open_device(device) │
│ 打开选定的 RDMA 设备 │
└──────────────────────────────────────────┘
↓
返回设备上下文
├─ struct ibv_context
├─ 包含设备信息
└─ 用于后续操作
关键信息:
- 返回
struct ibv_context * - 包含设备的所有信息
- 需要手动释放:
ibv_close_device()
Step 3: 查询设备属性
┌──────────────────────────────────────────┐
│ ibv_query_device(context, &attr) │
│ 获取设备的详细属性 │
└──────────────────────────────────────────┘
↓
返回设备属性
├─ max_qp: 最大队列对数
├─ max_cq: 最大完成队列数
├─ max_mr: 最大内存区域数
├─ max_qp_wr: 队列对最大工作请求
├─ max_sge: 最大分散聚集元素
├─ max_mr_size: 最大内存注册大小
└─ hw_ver: 硬件版本
关键信息:
- 了解硬件能力
- 用于资源规划
- 返回
struct ibv_device_attr
Step 4: 分配保护域(Protection Domain)
┌──────────────────────────────────────────┐
│ ibv_alloc_pd(context) │
│ 为设备分配保护域 │
└──────────────────────────────────────────┘
↓
返回保护域
├─ struct ibv_pd
├─ 用于内存注册
├─ 用于队列对创建
└─ 用于完成队列创建
关键信息:
- PD 是内存和队列对的容器
- 同一 PD 内的资源可以相互访问
- 需要手动释放:
ibv_dealloc_pd()
Step 5: 创建完成队列(Completion Queue)
┌──────────────────────────────────────────┐
│ ibv_create_cq(context, cqe, NULL, NULL) │
│ 创建完成队列 │
└──────────────────────────────────────────┘
↓
返回完成队列
├─ struct ibv_cq
├─ cqe: 完成队列元素数
├─ 用于接收完成事件
└─ 用于轮询完成状态
关键信息:
- CQ 用于接收操作完成通知
- 可以为 Send CQ 和 Recv CQ 创建不同的队列
- 也可以共用一个 CQ
Step 6: 创建队列对(Queue Pair)
┌──────────────────────────────────────────────────────┐
│ ibv_create_qp(pd, &qp_init_attr) │
│ 创建队列对(RDMA 通信的核心) │
└──────────────────────────────────────────────────────┘
↓
返回队列对
├─ struct ibv_qp
├─ qp_num: 队列对号
├─ send_cq: Send 完成队列
├─ recv_cq: Recv 完成队列
├─ sq_psn: Send 包序列号
├─ rq_psn: Recv 包序列号
└─ qp_state: 初始状态 (RESET)
关键信息:
- QP 是 RDMA 通信的基本单位
- 需要配置
struct ibv_qp_init_attr - 初始状态为 RESET
- 需要手动释放:
ibv_destroy_qp()
QP 初始化属性:
struct ibv_qp_init_attr {
void *qp_context; // 用户定义的上下文
struct ibv_cq *send_cq; // Send 完成队列
struct ibv_cq *recv_cq; // Recv 完成队列
struct ibv_srq *srq; // 共享接收队列(可选)
struct ibv_qp_cap cap; // 队列对能力
enum ibv_qp_type qp_type; // 队列对类型(IBV_QPT_RC/UC/UD)
int sq_sig_all; // 是否所有 Send 都生成完成事件
};
Step 7: 注册内存区域(Memory Region)
┌──────────────────────────────────────────┐
│ ibv_reg_mr(pd, buf, size, access) │
│ 注册用于 RDMA 的内存区域 │
└──────────────────────────────────────────┘
↓
返回内存区域
├─ struct ibv_mr
├─ addr: 内存地址
├─ length: 内存大小
├─ lkey: 本地密钥(用于 Send/Recv)
├─ rkey: 远程密钥(用于 RDMA Write/Read)
└─ 用于数据传输
关键信息:
- 必须注册所有用于 RDMA 的内存
- 注册会锁定内存(防止 swap)
- lkey 用于本地操作
- rkey 用于远程操作
- 需要手动释放:
ibv_dereg_mr()
访问权限:
enum ibv_access_flags {
IBV_ACCESS_LOCAL_WRITE = 1, // 本地写
IBV_ACCESS_REMOTE_WRITE = (1 << 1), // 远程写
IBV_ACCESS_REMOTE_READ = (1 << 2), // 远程读
IBV_ACCESS_REMOTE_ATOMIC = (1 << 3), // 远程原子操作
IBV_ACCESS_MW_BIND = (1 << 4), // 内存窗口绑定
};
Step 8: 建立连接(可选)
┌──────────────────────────────────────────┐
│ 修改 QP 状态 │
│ RESET → INIT → RTR → RTS │
└──────────────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ RESET (初始状态) │
│ ↓ ibv_modify_qp() │
│ INIT (初始化) │
│ ↓ ibv_modify_qp() │
│ RTR (Ready to Receive) │
│ ↓ ibv_modify_qp() │
│ RTS (Ready to Send) │
│ ✅ 可以发送和接收数据 │
└─────────────────────────────────┘
QP 状态转换:
// RESET → INIT
struct ibv_qp_attr attr = {
.qp_state = IBV_QPS_INIT,
.pkey_index = 0,
.port_num = 1,
.qp_access_flags = IBV_ACCESS_REMOTE_WRITE | IBV_ACCESS_REMOTE_READ,
};
ibv_modify_qp(qp, &attr, IBV_QP_STATE | IBV_QP_PKEY_INDEX |
IBV_QP_PORT | IBV_QP_ACCESS_FLAGS);
// INIT → RTR
attr.qp_state = IBV_QPS_RTR;
attr.path_mtu = IBV_MTU_1024;
attr.dest_qp_num = remote_qp_num;
attr.rq_psn = remote_psn;
// ... 设置其他属性
ibv_modify_qp(qp, &attr, ...);
// RTR → RTS
attr.qp_state = IBV_QPS_RTS;
attr.sq_psn = local_psn;
attr.timeout = 14;
attr.retry_cnt = 7;
attr.rnr_retry = 7;
ibv_modify_qp(qp, &attr, ...);
数据路径(DP)流程
数据路径概览
┌─────────────────────────────────────────────────────────────┐
│ RDMA 数据路径流程 │
└─────────────────────────────────────────────────────────────┘
应用程序
↓
┌──────────────────────────────────────────┐
│ 1. 准备工作请求(Work Request) │
│ - Send WR / Recv WR │
│ - 设置数据缓冲区和长度 │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 2. 提交工作请求到队列对 │
│ - ibv_post_send() / ibv_post_recv() │
│ - 请求进入 SQ / RQ │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 3. 网卡处理请求 │
│ - 从队列中取出请求 │
│ - 执行 RDMA 操作 │
│ - 生成完成事件 │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 4. 轮询或等待完成事件 │
│ - ibv_poll_cq() / ibv_get_cq_event() │
│ - 获取完成状态 │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 5. 处理完成事件 │
│ - 检查操作状态 │
│ - 处理数据 │
│ - 继续下一个操作 │
└──────────────────────────────────────────┘
详细数据路径步骤
Step 1: 准备工作请求(Work Request)
┌─────────────────────────────────────────────────┐
│ struct ibv_send_wr / struct ibv_recv_wr │
│ 定义要执行的 RDMA 操作 │
└─────────────────────────────────────────────────┘
Send Work Request 结构:
┌──────────────────────────────────────────┐
│ struct ibv_send_wr { │
│ uint64_t wr_id; // 工作请求ID │
│ struct ibv_send_wr *next; // 链表指针 │
│ struct ibv_sge *sg_list; // 分散聚集 │
│ int num_sge; // SGE 数量 │
│ enum ibv_wr_opcode opcode; // 操作类型 │
│ int send_flags; // 发送标志 │
│ union { │
│ struct { │
│ uint32_t remote_qpn; // 远程 QPN │
│ uint32_t remote_qkey; // 远程 QKEY │
│ } ud; │
│ struct { │
│ uint64_t remote_addr; // 远程地址 │
│ uint32_t rkey; // 远程密钥 │
│ } rdma; │
│ }; │
│ }; │
└──────────────────────────────────────────┘
Recv Work Request 结构:
┌──────────────────────────────────────────┐
│ struct ibv_recv_wr { │
│ uint64_t wr_id; // 工作请求ID │
│ struct ibv_recv_wr *next; // 链表指针 │
│ struct ibv_sge *sg_list; // 分散聚集 │
│ int num_sge; // SGE 数量 │
│ }; │
└──────────────────────────────────────────┘
分散聚集元素(SGE):
┌──────────────────────────────────────────┐
│ struct ibv_sge { │
│ uint64_t addr; // 内存地址 │
│ uint32_t length; // 数据长度 │
│ uint32_t lkey; // 本地密钥 │
│ }; │
└──────────────────────────────────────────┘
操作类型(opcode):
enum ibv_wr_opcode {
IBV_WR_SEND, // Send 操作
IBV_WR_SEND_WITH_IMM, // Send with Immediate
IBV_WR_RDMA_WRITE, // RDMA Write
IBV_WR_RDMA_WRITE_WITH_IMM, // RDMA Write with Immediate
IBV_WR_RDMA_READ, // RDMA Read
IBV_WR_ATOMIC_CMP_AND_SWP, // 原子比较交换
IBV_WR_ATOMIC_FETCH_AND_ADD, // 原子加
IBV_WR_LOCAL_INV, // 本地失效
IBV_WR_BIND_MW, // 绑定内存窗口
IBV_WR_SEND_WITH_INV, // Send with Invalidate
};
Step 2: 提交工作请求到队列对
┌─────────────────────────────────────────────────┐
│ ibv_post_send(qp, &wr, &bad_wr) │
│ 或 │
│ ibv_post_recv(qp, &wr, &bad_wr) │
│ 提交工作请求到队列对 │
└─────────────────────────────────────────────────┘
应用程序
↓
┌──────────────────────────────────────┐
│ 工作请求链表 │
│ wr1 → wr2 → wr3 → NULL │
└──────────────────────────────────────┘
↓
┌──────────────────────────────────────┐
│ ibv_post_send() / ibv_post_recv() │
│ 验证请求 │
│ 检查队列空间 │
│ 提交到硬件队列 │
└──────────────────────────────────────┘
↓
┌──────────────────────────────────────┐
│ 队列对(QP) │
│ ┌──────────────────────────────────┐ │
│ │ Send Queue (SQ) │ │
│ │ [WR1] [WR2] [WR3] [ ] [ ] │ │
│ └──────────────────────────────────┘ │
│ ┌──────────────────────────────────┐ │
│ │ Recv Queue (RQ) │ │
│ │ [WR1] [WR2] [ ] [ ] [ ] │ │
│ └──────────────────────────────────┘ │
└──────────────────────────────────────┘
关键信息:
- 可以一次提交多个 WR(链表形式)
- 如果失败,
bad_wr指向第一个失败的 WR - 返回值:0 表示成功,-1 表示失败
Step 3: 网卡处理请求
┌─────────────────────────────────────────────────┐
│ 网卡硬件处理 │
└─────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────┐
│ 网卡处理流程 │
├──────────────────────────────────────────────────┤
│ │
│ 1. 从 SQ 取出工作请求 │
│ ↓ │
│ 2. 解析请求参数 │
│ - 操作类型(Send/RDMA Write/Read) │
│ - 数据地址和长度 │
│ - 远程地址和密钥(如果是 RDMA 操作) │
│ ↓ │
│ 3. 执行 RDMA 操作 │
│ ├─ Send: 发送数据到远程 QP │
│ ├─ RDMA Write: 写数据到远程内存 │
│ ├─ RDMA Read: 从远程内存读数据 │
│ └─ Atomic: 执行原子操作 │
│ ↓ │
│ 4. 生成完成事件 │
│ - 写入完成队列(CQ) │
│ - 触发中断(如果启用) │
│ ↓ │
│ 5. 更新队列指针 │
│ - 从 SQ 中移除已处理的 WR │
│ ↓ │
│ ✅ 操作完成 │
│ │
└──────────────────────────────────────────────────┘
RDMA 操作类型:
Send 操作:
┌─────────────┐ ┌─────────────┐
│ 发送端 QP │ ──────→ │ 接收端 QP │
│ Send WR │ 网络 │ Recv WR │
└─────────────┘ └─────────────┘
数据进入 RQ,触发完成事件
RDMA Write 操作(One-Sided):
┌─────────────┐ ┌─────────────┐
│ 发送端 QP │ ──────→ │ 远程内存 │
│ RDMA Write │ 网络 │ (无需 QP) │
└─────────────┘ └─────────────┘
直接写入远程内存,无需远程 CPU 参与
RDMA Read 操作(One-Sided):
┌─────────────┐ ┌─────────────┐
│ 发送端 QP │ ←────── │ 远程内存 │
│ RDMA Read │ 网络 │ (无需 QP) │
└─────────────┘ └─────────────┘
直接从远程内存读取数据,无需远程 CPU 参与
Step 4: 轮询或等待完成事件
┌─────────────────────────────────────────────────┐
│ ibv_poll_cq(cq, num_entries, wc) │
│ 或 │
│ ibv_get_cq_event(channel, &cq, &cq_context) │
│ 获取完成事件 │
└─────────────────────────────────────────────────┘
完成队列(CQ)结构:
┌──────────────────────────────────────────┐
│ struct ibv_cq { │
│ struct ibv_context *context; │
│ struct ibv_comp_channel *channel; │
│ void *cq_context; │
│ uint32_t handle; │
│ int cqe; │
│ }; │
└──────────────────────────────────────────┘
完成工作条目(WC)结构:
┌──────────────────────────────────────────┐
│ struct ibv_wc { │
│ uint64_t wr_id; // 工作请求 ID │
│ enum ibv_wc_status status; // 完成状态 │
│ enum ibv_wc_opcode opcode; // 操作类型 │
│ uint32_t vendor_err; // 厂商错误码 │
│ uint32_t byte_len; // 传输字节数 │
│ uint32_t imm_data; // Immediate 数据│
│ uint32_t qp_num; // 队列对号 │
│ uint32_t src_qp; // 源 QP 号 │
│ int wc_flags; // 完成标志 │
│ uint16_t pkey_index; // 分区键索引 │
│ uint16_t slid; // 源 LID │
│ uint8_t sl; // 服务级别 │
│ uint8_t dlid_path_bits; // DLID 路径位 │
│ }; │
└──────────────────────────────────────────┘
轮询方式(Polling):
┌──────────────────────────────────────────┐
│ while (1) { │
│ int ne = ibv_poll_cq(cq, 10, wc); │
│ if (ne > 0) { │
│ for (int i = 0; i < ne; i++) { │
│ // 处理完成事件 │
│ if (wc[i].status != IBV_WC_SUCCESS)│
│ // 错误处理 │
│ } │
│ } │
│ } │
└──────────────────────────────────────────┘
事件驱动方式(Event-Driven):
┌──────────────────────────────────────────┐
│ // 请求完成事件通知 │
│ ibv_req_notify_cq(cq, 0); │
│ │
│ // 等待事件 │
│ struct ibv_cq *ev_cq; │
│ void *ev_ctx; │
│ ibv_get_cq_event(channel, &ev_cq, │
│ &ev_ctx); │
│ │
│ // 确认事件 │
│ ibv_ack_cq_events(cq, 1); │
│ │
│ // 轮询获取完成条目 │
│ int ne = ibv_poll_cq(cq, 10, wc); │
└──────────────────────────────────────────┘
完成状态(status):
enum ibv_wc_status {
IBV_WC_SUCCESS, // 成功
IBV_WC_LOC_LEN_ERR, // 本地长度错误
IBV_WC_LOC_QP_OP_ERR, // 本地 QP 操作错误
IBV_WC_LOC_EEC_OP_ERR, // 本地 EEC 操作错误
IBV_WC_LOC_PROT_ERR, // 本地保护错误
IBV_WC_WR_FLUSH_ERR, // 工作请求刷新错误
IBV_WC_MW_BIND_ERR, // 内存窗口绑定错误
IBV_WC_BAD_RESP_ERR, // 坏响应错误
IBV_WC_LOC_ACCESS_ERR, // 本地访问错误
IBV_WC_REM_INV_REQ_ERR, // 远程无效请求错误
IBV_WC_REM_ACCESS_ERR, // 远程访问错误
IBV_WC_REM_OP_ERR, // 远程操作错误
IBV_WC_RETRY_EXC_ERR, // 重试超限错误
IBV_WC_RNR_RETRY_EXC_ERR, // RNR 重试超限错误
IBV_WC_LOC_RDD_VIOL_ERR, // 本地 RDD 违规错误
IBV_WC_REM_INVALID_RD_REQ_ERR, // 远程无效 RD 请求错误
IBV_WC_REM_ABORT_ERR, // 远程中止错误
IBV_WC_INV_EECN_ERR, // 无效 EECN 错误
IBV_WC_INV_EEC_STATE_ERR, // 无效 EEC 状态错误
IBV_WC_FATAL_ERR, // 致命错误
IBV_WC_RESP_TIMEOUT_ERR, // 响应超时错误
IBV_WC_GENERAL_ERR, // 通用错误
};
Step 5: 处理完成事件
┌─────────────────────────────────────────────────┐
│ 处理完成工作条目(WC) │
└─────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────┐
│ 完成事件处理流程 │
├──────────────────────────────────────────────────┤
│ │
│ 1. 检查完成状态 │
│ if (wc.status != IBV_WC_SUCCESS) { │
│ // 错误处理 │
│ fprintf(stderr, "Error: %s\n", │
│ ibv_wc_status_str(wc.status)); │
│ return -1; │
│ } │
│ ↓ │
│ 2. 根据操作类型处理 │
│ switch (wc.opcode) { │
│ case IBV_WC_SEND: │
│ // Send 操作完成 │
│ printf("Send completed\n"); │
│ break; │
│ case IBV_WC_RECV: │
│ // Recv 操作完成 │
│ printf("Received %d bytes\n", │
│ wc.byte_len); │
│ break; │
│ case IBV_WC_RDMA_WRITE: │
│ // RDMA Write 完成 │
│ printf("RDMA Write completed\n"); │
│ break; │
│ case IBV_WC_RDMA_READ: │
│ // RDMA Read 完成 │
│ printf("RDMA Read completed\n"); │
│ break; │
│ } │
│ ↓ │
│ 3. 处理数据 │
│ // 根据 wr_id 找到对应的数据缓冲区 │
│ struct buffer *buf = find_buffer(wc.wr_id); │
│ process_data(buf, wc.byte_len); │
│ ↓ │
│ 4. 继续下一个操作 │
│ // 如果需要,提交新的工作请求 │
│ submit_next_wr(qp); │
│ ↓ │
│ ✅ 处理完成 │
│ │
└──────────────────────────────────────────────────┘
代码示例
完整的初始化示例
#include <infiniband/verbs.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
// Step 1: 获取设备列表
int num_devices;
struct ibv_device **dev_list = ibv_get_device_list(&num_devices);
if (!dev_list) {
fprintf(stderr, "Failed to get device list\n");
return -1;
}
printf("Found %d RDMA devices\n", num_devices);
// Step 2: 打开第一个设备
struct ibv_context *context = ibv_open_device(dev_list[0]);
if (!context) {
fprintf(stderr, "Failed to open device\n");
ibv_free_device_list(dev_list);
return -1;
}
printf("Device opened successfully\n");
// Step 3: 查询设备属性
struct ibv_device_attr device_attr;
if (ibv_query_device(context, &device_attr)) {
fprintf(stderr, "Failed to query device\n");
ibv_close_device(context);
ibv_free_device_list(dev_list);
return -1;
}
printf("Max QP: %d, Max CQ: %d, Max MR: %d\n",
device_attr.max_qp, device_attr.max_cq, device_attr.max_mr);
// Step 4: 分配保护域
struct ibv_pd *pd = ibv_alloc_pd(context);
if (!pd) {
fprintf(stderr, "Failed to allocate PD\n");
ibv_close_device(context);
ibv_free_device_list(dev_list);
return -1;
}
printf("PD allocated successfully\n");
// Step 5: 创建完成队列
struct ibv_cq *cq = ibv_create_cq(context, 100, NULL, NULL, 0);
if (!cq) {
fprintf(stderr, "Failed to create CQ\n");
ibv_dealloc_pd(pd);
ibv_close_device(context);
ibv_free_device_list(dev_list);
return -1;
}
printf("CQ created successfully\n");
// Step 6: 创建队列对
struct ibv_qp_init_attr qp_init_attr = {
.qp_context = NULL,
.send_cq = cq,
.recv_cq = cq,
.srq = NULL,
.cap = {
.max_send_wr = 100,
.max_recv_wr = 100,
.max_send_sge = 1,
.max_recv_sge = 1,
.max_inline_data = 0,
},
.qp_type = IBV_QPT_RC,
.sq_sig_all = 0,
};
struct ibv_qp *qp = ibv_create_qp(pd, &qp_init_attr);
if (!qp) {
fprintf(stderr, "Failed to create QP\n");
ibv_destroy_cq(cq);
ibv_dealloc_pd(pd);
ibv_close_device(context);
ibv_free_device_list(dev_list);
return -1;
}
printf("QP created successfully (QP number: %d)\n", qp->qp_num);
// Step 7: 注册内存区域
char *buf = malloc(4096);
struct ibv_mr *mr = ibv_reg_mr(pd, buf, 4096,
IBV_ACCESS_LOCAL_WRITE |
IBV_ACCESS_REMOTE_WRITE |
IBV_ACCESS_REMOTE_READ);
if (!mr) {
fprintf(stderr, "Failed to register MR\n");
free(buf);
ibv_destroy_qp(qp);
ibv_destroy_cq(cq);
ibv_dealloc_pd(pd);
ibv_close_device(context);
ibv_free_device_list(dev_list);
return -1;
}
printf("MR registered successfully (lkey: %d, rkey: %d)\n",
mr->lkey, mr->rkey);
// 清理资源
ibv_dereg_mr(mr);
free(buf);
ibv_destroy_qp(qp);
ibv_destroy_cq(cq);
ibv_dealloc_pd(pd);
ibv_close_device(context);
ibv_free_device_list(dev_list);
printf("Initialization completed successfully!\n");
return 0;
}
数据路径示例
// Send 操作
struct ibv_sge sge = {
.addr = (uintptr_t)buf,
.length = 256,
.lkey = mr->lkey,
};
struct ibv_send_wr send_wr = {
.wr_id = 1,
.next = NULL,
.sg_list = &sge,
.num_sge = 1,
.opcode = IBV_WR_SEND,
.send_flags = IBV_SEND_SIGNALED,
};
struct ibv_send_wr *bad_wr;
if (ibv_post_send(qp, &send_wr, &bad_wr)) {
fprintf(stderr, "Failed to post send\n");
return -1;
}
// 轮询完成事件
struct ibv_wc wc;
int ne = ibv_poll_cq(cq, 1, &wc);
if (ne > 0) {
if (wc.status == IBV_WC_SUCCESS) {
printf("Send completed successfully\n");
} else {
printf("Send failed: %s\n", ibv_wc_status_str(wc.status));
}
}
常见问题
Q1: PD、CQ、QP 之间的关系是什么?
PD (保护域)
├─ 用于内存注册
├─ 用于创建 QP
└─ 同一 PD 内的资源可以相互访问
CQ (完成队列)
├─ 接收 Send 操作的完成事件
├─ 接收 Recv 操作的完成事件
└─ 可以为 Send 和 Recv 使用不同的 CQ
QP (队列对)
├─ 属于某个 PD
├─ 使用某个 CQ(或多个 CQ)
└─ 是 RDMA 通信的基本单位
Q2: lkey 和 rkey 有什么区别?
- lkey:本地密钥,用于本地操作(Send/Recv)
- rkey:远程密钥,用于远程操作(RDMA Write/Read)
Q3: 为什么需要注册内存?
- 锁定内存,防止被 swap 到磁盘
- 获取 lkey 和 rkey,用于 RDMA 操作
- 网卡需要知道内存的物理地址
Q4: QP 状态转换的顺序是什么?
RESET → INIT → RTR → RTS
- RESET:初始状态
- INIT:初始化状态
- RTR:Ready to Receive,可以接收数据
- RTS:Ready to Send,可以发送数据
Q5: Send 和 RDMA Write 有什么区别?
Send:
- 两端都需要 QP
- 接收端需要提前 post recv
- 数据进入接收端的 RQ
- 需要接收端的 CPU 参与
RDMA Write:
- 只需要发送端的 QP
- 接收端不需要参与
- 直接写入远程内存
- 接收端的 CPU 不需要参与
总结
初始化流程(8 步)
- 获取设备列表
- 打开设备
- 查询设备属性
- 分配保护域
- 创建完成队列
- 创建队列对
- 注册内存区域
- 建立连接(修改 QP 状态)
数据路径流程(5 步)
- 准备工作请求
- 提交工作请求
- 网卡处理请求
- 轮询或等待完成事件
- 处理完成事件
更多资源:
dpdk
DPDK 专栏,基于 官方 http://doc.dpdk.org/guides/prog_guide/ 的 program guide,从代码中验证相关实现细节。
官方文档中的每一个章节,会有相应的技术实现细节。
章节目录(Draft)
- 00:专栏导读与阅读方法
- 01:EAL 初始化与 lcore/线程模型
- 02:Hugepage/内存子系统
- 03:mempool 机制
- 04:mbuf 与 pktmbuf 分配路径
- 05:ring / rte_ring
- 06:ethdev 抽象
- 07:PMD 驱动加载与探测
- 08:RX/TX 数据通路
- 09:multi-process 与 IPC
- 10:service cores 与调度
- 11:telemetry / stats / debug
- 12:flow/ACL 规则下发
- 13:vhost-user / virtio-user
- 14:性能调优方法论
实现进度(手工维护)
状态枚举:
- 未开始:仅有章节骨架
- 进行中:正在阅读源码/补图/补验证
- 已完成:主流程 + 关键数据结构 + 可复现验证已补齐
- 待重构:内容需要重写/拆分/补证据链
| 章节 | 状态 | 里程碑/完成度 | 备注(代码阅读路径/关键点) | 最后更新 |
|---|---|---|---|---|
| 00:专栏导读与阅读方法 | 已完成 | 100% | 建立 Program Guide ↔ /home/panda/dpdk 源码映射与写作模板 | 2026-03-16 |
| 01:EAL 初始化与 lcore/线程模型 | 已完成 | 100% | lib/eal/linux/eal.c:rte_eal_init()、IOVA 选择、bus scan | 2026-03-16 |
| 02:Hugepage/内存子系统 | 已完成 | 100% | lib/eal/common/eal_common_memory.c:memseg_list/virt↔iova | 2026-03-16 |
| 03:mempool 机制 | 已完成 | 100% | lib/mempool/rte_mempool.c:ops 选择、per-lcore cache、cookies | 2026-03-16 |
| 04:mbuf 与 pktmbuf 分配路径 | 已完成 | 100% | lib/mbuf/rte_mbuf.c:pool_create/extbuf/sanity check | 2026-03-16 |
| 05:ring / rte_ring | 已完成 | 100% | lib/ring/rte_ring_core.h + lib/ring/rte_ring.c:head/tail、flags | 2026-03-16 |
| 06:ethdev 抽象 | 已完成 | 100% | lib/ethdev/rte_ethdev.c:rte_eth_devices[]、rte_eth_fp_ops[] | 2026-03-16 |
| 07:PMD 驱动加载与探测 | 已完成 | 100% | lib/eal/common/eal_common_bus.c + drivers/bus/pci/* | 2026-03-16 |
| 08:RX/TX 数据通路 | 已完成 | 100% | ethdev fp_ops → PMD rx_burst/tx_burst;offload 传递链路 | 2026-03-16 |
| 09:multi-process 与 IPC | 已完成 | 100% | lib/eal/common/eal_common_proc.c:UDS + SCM_RIGHTS + mp-msg thread | 2026-03-16 |
| 10:service cores 与调度 | 已完成 | 100% | lib/eal/common/rte_service.c:register/runstate/stats;示例 examples/service_cores | 2026-03-16 |
| 11:telemetry / stats / debug | 已完成 | 100% | lib/telemetry/*、lib/metrics/*telemetry*、ethdev stats/xstats | 2026-03-16 |
| 12:flow/ACL 规则下发 | 已完成 | 100% | lib/ethdev/rte_flow.c/h + examples/flow_filtering + PMD flow 实现 | 2026-03-16 |
| 13:vhost-user / virtio-user | 已完成 | 100% | lib/vhost/*:register、协议处理、vring 数据面;示例 examples/vhost | 2026-03-16 |
| 14:性能调优方法论 | 已完成 | 100% | pinning/NUMA → mempool/ring/mbuf → queue/RSS → offload → profiling | 2026-03-16 |
lpm算法
网上对于 DPDK LPM 算法的描述都有点不清不楚的,还不如官方的描述。
我这里就结合官方的 文档,然后结合我自己的理解把优劣都说一下。
原理
LPM(Longest Prefix Match,最长前缀匹配)是 IP 路由转发中的核心算法。对于一个目的 IP 地址,需要在路由表中找到与之匹配的、前缀最长的那条路由规则,并返回其 next hop。
DPDK 的 LPM 实现采用了 DIR-24-8 算法的变体,核心思路是:用空间换时间,通过预展开(prefix expansion)将查找操作压缩到 1~2 次内存访问。
基本数据结构
整个 LPM 实例由三层数据结构组成:
┌─────────────────────────────────────────────────────────────────┐
│ struct __rte_lpm │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ struct rte_lpm │ │
│ │ tbl24[2^24] ──────────────────────────────────────► │ │
│ │ *tbl8 ──────────────────────────────────────► │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ name[32] │
│ max_rules │
│ number_tbl8s │
│ rule_info[32] (每个 depth 一个 rte_lpm_rule_info) │
│ *rules_tbl (高层规则表,用于增删查) │
│ *v / rcu_mode / *dq (RCU 相关) │
└─────────────────────────────────────────────────────────────────┘
1. tbl24 —— 第一级查找表
// rte_lpm.h
#define RTE_LPM_TBL24_NUM_ENTRIES (1 << 24) // 16,777,216 个条目
struct rte_lpm_tbl_entry {
uint32_t next_hop :24; // next hop 或 tbl8 的 group 索引
uint32_t valid :1; // 该条目是否有效
uint32_t valid_group :1; // 0: 直接存 next_hop; 1: 指向 tbl8
uint32_t depth :6; // 匹配的规则深度(前缀长度)
};
每个条目 4 字节,整张表共 64 MB。以 IP 地址的高 24 位作为索引。
valid_group 字段是关键标志:
valid_group == 0:该条目直接存储 next hop,查找在此结束valid_group == 1:该条目存储的是 tbl8 的 group 索引,需要继续查 tbl8
2. tbl8 —— 第二级查找表
// rte_lpm.h
#define RTE_LPM_TBL8_GROUP_NUM_ENTRIES 256 // 每个 group 256 个条目
#define RTE_LPM_TBL8_NUM_GROUPS 256 // 默认 256 个 group(可配置)
tbl8 由若干个 group 组成,每个 group 有 256 个 rte_lpm_tbl_entry,以 IP 地址的低 8 位作为索引。
对于 tbl8 中的条目,valid_group 字段含义变为:当前 tbl8 group 是否正在使用(而非指向下一级)。
3. rules_tbl —— 高层规则表
// rte_lpm.c (内部结构)
struct rte_lpm_rule {
uint32_t ip; // 规则的 IP 地址(已按 depth 做掩码)
uint32_t next_hop; // 下一跳
};
struct rte_lpm_rule_info {
uint32_t used_rules; // 该 depth 已使用的规则数
uint32_t first_rule; // 该 depth 规则在 rules_tbl 中的起始索引
};
rules_tbl 是一个平坦数组,按 depth 分组存储所有规则。rule_info[32] 数组记录每个 depth(1~32)的规则起始位置和数量。
这张表不参与数据面查找,仅用于控制面的增删操作(检查规则是否存在、删除时寻找替代规则等)。
整体结构关系图
graph TD
subgraph "__rte_lpm(控制面 + 数据面)"
A["rules_tbl[]<br/>高层规则表<br/>按 depth 分组"]
B["rule_info[32]<br/>每个 depth 的<br/>起始位置和数量"]
C["tbl24[2^24]<br/>第一级查找表<br/>以 IP[31:8] 为索引"]
D["tbl8[N × 256]<br/>第二级查找表<br/>以 IP[7:0] 为索引"]
end
B -->|"记录偏移"| A
C -->|"valid_group=1 时<br/>group_idx 指向"| D
C -->|"valid_group=0 时<br/>直接返回 next_hop"| E["next_hop"]
D -->|"valid=1 时<br/>返回 next_hop"| E
tbl_entry 字段布局(小端)
31 8 7 6 5 1 0
┌──────────┬───────┬──────────┬───────┐
│ next_hop │ depth │valid_grp │ valid │
│ [23:0] │ [5:0] │ [1] │ [0] │
└──────────┴───────┴──────────┴───────┘
优点:整个条目只有 4 字节,一次内存读取即可获取所有信息,对 CPU cache 非常友好。
Add Rules(添加规则)
添加一条规则 (ip, depth, next_hop) 分为两个阶段:
阶段一:更新 rules_tbl(控制面)
阶段二:更新 tbl24/tbl8(数据面)
阶段一:rule_add
// rte_lpm.c
static int32_t
rule_add(struct __rte_lpm *i_lpm, uint32_t ip_masked, uint8_t depth,
uint32_t next_hop)
rules_tbl 按 depth 分组,各组在数组中紧密排列。添加新规则时,需要将更高 depth 的规则整体后移一位,为新规则腾出空间:
添加前(depth=20 的规则组后面紧跟 depth=25 的规则组):
┌────────────────┬────────────────┬────────────────┐
│ depth=20 组 │ depth=25 组 │ (空闲) │
└────────────────┴────────────────┴────────────────┘
添加 depth=20 的新规则后:
┌─────────────────┬────────────────┬────────────────┐
│ depth=20 组+1 │ depth=25 组 │ (空闲) │
└─────────────────┴────────────────┴────────────────┘
(depth=25 组的 first_rule 指针 +1,整体后移)
若规则已存在(相同 ip_masked + depth),且nexthop相同,返回 -EEXIST,不需要更新数据面。
如果next_hop 不相同, 则更新 next_hop,需要更新数据面。
阶段二:更新数据面
根据 depth 的大小,走不同的路径:
// rte_lpm.c: rte_lpm_add
if (depth <= MAX_DEPTH_TBL24) { // depth ∈ [1, 24]
status = add_depth_small(...);
} else { // depth ∈ [25, 32]
status = add_depth_big(...);
}
add_depth_small(depth ≤ 24)
核心是前缀展开(Prefix Expansion):
一条 depth=20 的规则,意味着有 2^(24-20) = 16 个 tbl24 索引都能匹配到它,因此需要将这 16 个 tbl24 条目全部填写。
// rte_lpm.c: add_depth_small
tbl24_index = ip >> 8;
tbl24_range = depth_to_range(depth); // = 1 << (24 - depth)
for (i = tbl24_index; i < (tbl24_index + tbl24_range); i++) {
// 只覆盖无效条目,或 depth 更浅(优先级更低)的条目
if (!tbl24[i].valid || (tbl24[i].valid_group == 0 &&
tbl24[i].depth <= depth)) {
// 直接写入 next_hop,valid_group = 0
__atomic_store(&tbl24[i], &new_tbl24_entry, __ATOMIC_RELEASE);
}
// 若该 tbl24 条目已经扩展到 tbl8,则同步更新 tbl8 中 depth 更浅的条目
if (tbl24[i].valid_group == 1) {
// 遍历整个 tbl8 group,更新 depth <= 当前 depth 的条目
for (j = tbl8_index; j < tbl8_group_end; j++) {
if (!tbl8[j].valid || tbl8[j].depth <= depth)
__atomic_store(&tbl8[j], &new_tbl8_entry, __ATOMIC_RELAXED);
}
}
}
示例:添加规则 10.0.0.0/20(depth=20)
IP 高 24 位范围:0x0A0000 ~ 0x0A000F(共 16 个)
tbl24:
index: 0x0A0000 0x0A0001 ... 0x0A000F
[nh=X,d=20] [nh=X,d=20] ... [nh=X,d=20]
valid_group=0(直接命中,无需查 tbl8)
add_depth_big(depth > 24)
depth > 24 时,tbl24 只有一个条目对应该规则(高 24 位唯一确定),需要借助 tbl8 存储低 8 位的区分信息。
分三种情况:
情况 1:tbl24 条目无效(全新)
1. 分配一个空闲的 tbl8 group: 注意,分配逻辑只看 tbl8 group 第一个的entry 的valid_group 是否为1
2. 在 tbl8 group 中,将 [ip & 0xFF, ip & 0xFF + range) 范围的条目写入 next_hop
3. 将 tbl24 条目更新为:valid=1, valid_group=1, group_idx=<tbl8 group 索引>
(先写 tbl8,再写 tbl24,保证原子性)
情况 2:tbl24 条目有效但未扩展(valid_group=0,已有 depth≤24 的规则)
1. 分配一个空闲的 tbl8 group
2. 用 tbl24 中已有的 next_hop 填满整个 tbl8 group(继承旧规则): 为什么? 因为depth<= 24 的entry 很显然可以匹配上当前 tbl8 中的所有项目。
3. 再将 [ip & 0xFF, ip & 0xFF + range) 范围的条目覆盖为新 next_hop: 因为这个 range 的数据都可以匹配上这个ip,并且原先的 depth <= 24 的数据优先级没有这个entry 高
4. 将 tbl24 条目更新为指向新 tbl8 group =》 nexthop 指向 tbl8_group_index, valid group 为 1
情况 3:tbl24 条目已扩展(valid_group=1,已有 tbl8)
1. 直接找到对应的 tbl8 group =》 通过 tbl24 的 nexthop
2. 在 tbl8 group 中,将 [ip & 0xFF, ip & 0xFF + range) 范围内
depth 更浅的条目覆盖为新 next_hop
flowchart TD
A["rte_lpm_add(ip, depth, next_hop)"] --> B["rule_add: 更新 rules_tbl"]
B --> C{"depth ≤ 24?"}
C -->|是| D["add_depth_small<br/>前缀展开,填写 tbl24 范围条目<br/>range = 2^(24-depth)"]
C -->|否| E{"tbl24[ip>>8] valid以及valid group状态"}
E -->|"无效 (valid=0)"| F["分配 tbl8 group<br/>写入 tbl8 条目<br/>更新 tbl24 指向 tbl8"]
E -->|"有效且未扩展<br/>(valid_group=0)"| G["分配 tbl8 group<br/>用旧 next_hop 填满 tbl8<br/>覆盖新规则范围<br/>更新 tbl24 指向 tbl8"]
E -->|"有效且已扩展<br/>(valid_group=1)"| H["直接在已有 tbl8 group<br/>中覆盖对应范围条目"]
D --> I["完成"]
F --> I
G --> I
H --> I
关键设计:写 tbl8 和写 tbl24 的顺序很重要。代码中先用
__ATOMIC_RELAXED写 tbl8,再用__ATOMIC_RELEASE写 tbl24,确保读者看到 tbl24 的新值时,tbl8 的数据已经就绪,避免读到脏数据。
Del Rules(删除规则)
删除比添加复杂,因为删除一条规则后,原来被它覆盖的“更短前缀规则“需要被恢复出来。
整体流程
// rte_lpm.c: rte_lpm_delete
int rte_lpm_delete(struct rte_lpm *lpm, uint32_t ip, uint8_t depth)
flowchart TD
A["rte_lpm_delete(ip, depth)"] --> B["rule_find: 在 rules_tbl 中找到目标规则"]
B --> C{找到?}
C -->|否| Z["返回 -EINVAL"]
C -->|是| D["rule_delete: 从 rules_tbl 中删除"]
D --> E["find_previous_rule:<br/>在 rules_tbl 中找最长的替代规则<br/>(depth 更小、前缀匹配的规则)"]
E --> F{depth ≤ 24?}
F -->|是| G["delete_depth_small"]
F -->|否| H["delete_depth_big"]
G --> I["完成"]
H --> I
find_previous_rule —— 寻找替代规则
// rte_lpm.c
static int32_t
find_previous_rule(struct __rte_lpm *i_lpm, uint32_t ip, uint8_t depth,
uint8_t *sub_rule_depth)
{
// 从 depth-1 向下逐一查找,找到第一个匹配的规则
for (prev_depth = depth - 1; prev_depth > 0; prev_depth--) {
ip_masked = ip & depth_to_mask(prev_depth);
rule_index = rule_find(i_lpm, ip_masked, prev_depth);
if (rule_index >= 0) {
*sub_rule_depth = prev_depth;
return rule_index;
}
}
return -1; // 没有替代规则
}
例如:删除 10.0.0.0/24,若存在 10.0.0.0/16,则后者就是替代规则,删除后 tbl24 中对应条目应恢复为 /16 的 next_hop。
delete_depth_small(depth ≤ 24)
遍历 tbl24 中该规则覆盖的所有条目(range = 2^(24-depth) 个):
- 无替代规则:将 depth ≤ 被删规则 depth 的条目置为无效(
valid = 0) - 有替代规则:将 depth ≤ 被删规则 depth 的条目更新为替代规则的 next_hop 和 depth
对于已扩展到 tbl8 的条目,同样需要遍历整个 tbl8 group 做相同处理。
delete_depth_big(depth > 24)
只涉及一个 tbl24 条目和对应的 tbl8 group:
- 在 tbl8 group 中,将 depth ≤ 被删规则 depth 的条目置无效或更新为替代规则
- 检查 tbl8 group 是否可以回收(
tbl8_recycle_check):
// tbl8 回收判断逻辑(tbl8_recycle_check):
// 返回 -EINVAL:整个 group 全部无效 → 可以直接释放,tbl24 条目也置无效
// 返回 >= 0 :整个 group 的值完全相同且 depth ≤ 24 → 可以"折叠"回 tbl24
// 返回 -EEXIST:group 中还有不同的有效条目 → 不能回收
flowchart TD
A["tbl8_recycle_check"] --> B{第一个条目是否有效?}
B -->|无效| C["检查其余条目是否全部无效"]
C -->|全部无效| D["返回 -EINVAL<br/>(group 为空,可释放)"]
C -->|有有效条目| E["返回 -EEXIST<br/>(不能回收)"]
B -->|有效| F{depth ≤ 24?}
F -->|否| E
F -->|是| G["检查所有条目 depth 是否相同"]
G -->|相同| H["返回 group_start<br/>(可折叠回 tbl24)"]
G -->|不同| E
tbl8 回收的两种结果:
- 全空:先将 tbl24 条目的
valid置 0,再通过tbl8_free释放 tbl8 group - 可折叠:将 tbl8 group 中的值“提升“回 tbl24(
valid_group从 1 改为 0),再释放 tbl8 group
RCU 安全:
tbl8_free在有 RCU 时不会立即清零 tbl8,而是等待所有读者离开临界区(SYNC 模式)或将其加入延迟队列(DQ 模式),避免读者访问到已被清零的 tbl8 group。
Lookup Rules(查找规则)
查找是数据面热路径,实现为内联函数,极度优化:
// rte_lpm.h
static inline int
rte_lpm_lookup(struct rte_lpm *lpm, uint32_t ip, uint32_t *next_hop)
{
unsigned tbl24_index = (ip >> 8); // 取高 24 位作为 tbl24 索引
uint32_t tbl_entry;
const uint32_t *ptbl;
// 第一次内存访问:读 tbl24
ptbl = (const uint32_t *)(&lpm->tbl24[tbl24_index]);
tbl_entry = *ptbl;
// 判断是否需要查 tbl8(valid=1 且 valid_group=1)
if (unlikely((tbl_entry & RTE_LPM_VALID_EXT_ENTRY_BITMASK) ==
RTE_LPM_VALID_EXT_ENTRY_BITMASK)) {
// 第二次内存访问:读 tbl8
unsigned tbl8_index = (uint8_t)ip + // 低 8 位
((tbl_entry & 0x00FFFFFF) * // group_idx
RTE_LPM_TBL8_GROUP_NUM_ENTRIES); // × 256
ptbl = (const uint32_t *)&lpm->tbl8[tbl8_index];
tbl_entry = *ptbl;
}
*next_hop = (tbl_entry & 0x00FFFFFF); // 取低 24 位为 next_hop
return (tbl_entry & RTE_LPM_LOOKUP_SUCCESS) ? 0 : -ENOENT;
}
查找流程:
flowchart TD
A["输入:32-bit IP 地址"] --> B["tbl24_index = ip >> 8<br/>(取高 24 位)"]
B --> C["读取 tbl24[tbl24_index]<br/>第 1 次内存访问"]
C --> D{valid=1 且<br/>valid_group=1?}
D -->|否| E{valid=1?}
E -->|否| F["未命中,返回 -ENOENT"]
E -->|是| G["命中,返回 next_hop<br/>(tbl_entry 低 24 位)"]
D -->|是| H["tbl8_index = (ip & 0xFF)<br/>+ group_idx × 256"]
H --> I["读取 tbl8[tbl8_index]<br/>第 2 次内存访问"]
I --> J{valid=1?}
J -->|否| F
J -->|是| G
性能关键点
| 特性 | 说明 |
|---|---|
| 1~2 次内存访问 | 绝大多数路由(depth ≤ 24)只需 1 次 tbl24 访问 |
| 无锁读 | 查找路径完全无锁,依赖数据流依赖保证顺序,无需内存屏障 |
| SIMD 批量查找 | rte_lpm_lookupx4 利用 SSE/NEON 一次查找 4 个 IP |
| Cache 友好 | tbl24 条目 4 字节,64 字节 cache line 可容纳 16 个条目 |
批量查找(rte_lpm_lookup_bulk)
// 两阶段批量查找,充分利用内存级并行(MLP)
// 阶段 1:批量计算所有 tbl24 索引
for (i = 0; i < n; i++)
tbl24_indexes[i] = ips[i] >> 8;
// 阶段 2:批量读取 tbl24,按需读取 tbl8
for (i = 0; i < n; i++) {
next_hops[i] = tbl24[tbl24_indexes[i]];
if (需要查 tbl8)
next_hops[i] = tbl8[...];
}
两阶段设计让 CPU 可以预取后续的 tbl24 条目,隐藏内存延迟,在大批量查找时性能显著优于逐条查找。
优势
- 对于 24bit 以下的掩码,查找复杂度基本可以认为是o(1)的.
- 用了一个大数组,内存访问会比较友好
- rcu锁,读完全无锁 (普通的rwlock对cache很不友好,有很多文章都说了rwlock在一些场景下性能甚至不如mutex!)
- 这个设计很符合硬件的设计逻辑,适合硬件卸载
劣势
- 占用内存大,单个LPM表初始化之后占用就在 60M+
- KEY 无法扩展,只支持了 IPV4/IPV6,ipv6的字节足够长,可能通过构造也勉强能用
- nexthop 无法扩展,现在给的是portId, 实际使用的时候往往有更多的需求
- lpm add/del 最差情况下是o(n)的,主要开销是在 rule 的管理: 实际使用中还好,因为很多sdn网络也不会有那么快的路由变配。
mlx5驱动
mlx5驱动是给 mellanox CX6 网卡使用的。
它既有内核态的驱动,也有用户态符合 ibverbs 生态的用户态 驱动 。 可能 ibverbs 相关的内容也不能叫驱动。不过确实提供了访问网卡的路径。
此外,对于 DPDK ,它在使用 cx6 网卡时,使用ibverbs库作为访问网卡的途径。 所以在研究完前置条件之后,再把 DPDK 的使用方法再看一看。
OFED
firmware, driver 等,有一套专门的框架来管理,叫 OFED。
对于内核驱动,可以使用 kernel upstream 的驱动,但是这个更新的可能不如 OFED 那么快。厂商一般也是通过OFED来发行他们的网卡驱动,所以就从OFED入手。
使用的OFED为 MLNX_OFED_LINUX-5.14.0-2.0.1.myos.x86_64.tgz
linux Kernel Driver:
rdma-core
DPDK
debug_iptables
有些cni 如calico等还在使用iptables作为规则下发工具。
有的时候会出现丢包,这个时候就要去查看iptables,但这个工具列出的规则很抽象。
下面总结了常见的规则查看方法 和 debug 手段。
IP tables 四表5链
flowchart TD
A[PREROUTING <br/> raw->mangle->nat] --> B{Destination为本机}
B -->|是| C[Input <br/> mangle->filter]
C --> F[application]
B -->|否| D[FORWARD <br/> mangle->filter]
D --> E[POSTROUTING <br/> mangle->nat]
F --> G[OUTPUT <br/> raw->mangle->nat->filter]
G --> E
H[NIC] --> A
E --> H
注意,这只是一种典型实现。有的实现的链里面可能会有额外的表,比如说有点 input 链可能会有 nat表。具体情况具体分析。
比如通 iptable -L -n -t raw 就可以看出raw表所有的链。
- nat表: 会把一些nat规则放进来,通常在 prerouting, postrouting 的时候生效。也就是说路由之前把ip nat一下,让一个外部ip变成内部ip,然后在出网络的时候,再nat一下,让内部的ip变成外部的ip。
- raw表: 这个表一般没啥数据,通常在 PREROUTING 和 OUTPUT 链存在,可以用来做流量统计,TRACE 之类的。
- mangle表: 修改表,可以用来修改checksum之类的
- filter表: 过滤表,通常防火墙的实现在这里。这里就可以看到哪些流量会被reject/Drop掉等等。在 INPUT 和 FORWARD 以及 OUTPUT 三个点。
IP rules 解析
结合着例子来看
[root@localhost ~]# iptables -t filter -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
LIBVIRT_INP all -- 0.0.0.0/0 0.0.0.0/0
...
# 这里就是说,在 input 上,所有流量(前缀匹配)都到目标链 LIBVIRT_INP
# 使用下面的命令查看链上的数据,默认动作是pass
[root@localhost ~]# iptables -t filter -L LIBVIRT_INP -n
Chain LIBVIRT_INP (1 references)
target prot opt source destination
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:53
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:53
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:67
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:67
再有一个例子,比如说在虚拟机场景, 虚拟机创建的vm的nic绑定到nc的br0(192.168.1.1/24)口上。
可以按照这个操作来绑定
ip l add name br0 type bridge
virsh attach-interface demovm2 --type bridge --source br0 --model virtio #添加一块网卡,指定模式virtio网卡更快
ip a add 192.168.1.1/24 dev br0
也就是说 br0 作为虚拟网桥,连接vm 和 物理机。
假设现在通过qemu创建了一个vm,192.168.1.2/24, 一个场景是vm需要访问外部物理机器。
可以用 NAT 模式来实现这个功能(如果用过vmware,就知道了为什么它有个网卡模式叫nat模式)。
# vm发送到外界,比如说dns query 8.8.8.8,流量会从br0 口上收到, 进入 PREROUTING 链
# 但是这个ip不在物理机上,如果不开ip_forward,会直接被丢弃掉,所以首先将 net.ipv4.ip_forward 打开
sysctl -w net.ipv4.ip_forward=1
# 接下来,流量会依次经过 FOWARD 链,POSTROUTING 链
# 我们就在 POSTROUTING 链上操作,在nat表中添加一条 masquerade 动作
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o bond0 -j MASQUERADE
# 这个动作的意思就是,如果源在 192.168.1.0/24 并且出口是 bond0(也就是物理节点上的默认路由出口), 那么就执行 masquerade 动作
# masquerade 是对数据包进行伪装
# 具体的来说,将数据包的 源ip 和 port 进行 nat,然后记录到 conntrack 中
# 当外界的响应到时,在prerouting点通过conntrack将ip和port进行恢复,然后正常走后续路由流程
这样,两条命令,就完成了一个cni的一部分工作。
iptables debug
有的时候,tcpdump 能抓到包,但是应用又收不到数据。
知道就是 iptables 的规则导致,但是往往规则复杂,肉眼一时半会儿看不出来到底为什么丢包。
如果能够知道这个包经过什么流程,那就最好了,iptables 的trace模块就是解决了这个问题。
## 开启trace
modprobe ipt_LOG 2>/dev/null
modprobe ipt_TRACE 2>/dev/null
# 比如说抓 192.168.1.1 的icmp流量
iptables -t raw -I PREROUTING 1 -s 192.168.1.1 -p icmp -j TRACE
# TRACE 动作会把之后所有经过表/链以及动作都记录下来
# 之后可以通过下面命令来查看
dmesg | grep -i "TRACE:" -n
# 或者
journalctl -k | grep -i "TRACE:" -n
# 用完记得删除 TRACE 规则
iptables -t raw -D PREROUTING 1 -j TRACE
kernel
通用准备工作
在开始任何实验之前,请确保你的环境准备就绪:
虚拟机:安装一个 Linux 虚拟机(推荐 Ubuntu 22.04 LTS 或 Fedora),并创建快照,以便随时可以恢复到干净状态。
QEMU & GDB:搭建好 QEMU + GDB 内核调试环境。
内核源码:下载一份你感兴趣的内核源码(如最新的 LTS 版本)。
基础编译:你已经能够独立编译内核并用 QEMU 启动它。
领域一:eBPF 与 高级网络
实验 1:初窥门径 —— 使用 bpftrace 洞察内核
目标:不写一行 C 代码,直观感受 eBPF 的强大威力,学会使用高级工具进行即时追踪。
工具:bpftrace。
步骤:
安装 bpftrace:sudo apt install bpftrace (Ubuntu) 或 sudo dnf install bpftrace (Fedora)。
追踪系统调用:打开一个终端,运行 sudo bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("Opening file: %s\n", str(args->filename)); }'。
打开另一个终端,执行一些常见命令,如 ls /tmp,cat /etc/hosts。
观察第一个终端的输出,你会看到所有 openat 系统调用的文件路径都被实时打印出来。
尝试其他 bpftrace 单行命令,例如:sudo bpftrace -e 'kprobe:do_exit { printf("PID %d exited\n", pid); }' 来追踪进程退出。
验证与思考:
验证:是否能看到预期的输出?
思考:bpftrace 是如何做到在不修改、不重编译内核的情况下,获取到这些内部信息的?tracepoint 和 kprobe 有什么区别?
实验 2:登堂入室 —— 使用 BCC/Python 编写 eBPF 应用
目标:学会编写一个包含内核态 eBPF 代码和用户态控制程序的完整应用。
工具:BCC (BPF Compiler Collection), Python。
步骤:
安装 BCC:按照 BCC 安装指南 进行安装。
编写一个 Python 脚本 (hello_bcc.py)。
在脚本中,定义一段 C 语言的 eBPF 程序,该程序使用 kprobe 挂载到 clone 系统调用上,并使用 bpf_trace_printk 打印一条消息。
在 Python 部分,加载并挂载上述 eBPF 程序,然后循环读取 trace_pipe 来显示内核的输出。
运行脚本 sudo python3 hello_bcc.py,并在另一个终端创建新进程(如打开一个新的 shell),观察输出。
验证与思考:
验证:运行脚本后,创建新进程时,是否能看到内核打印的 "Hello, clone!" 之类的消息?
思考:用户态的 Python 脚本和内核态的 C 代码是如何交互的?bpf_trace_printk 是一种简单的调试方式,在生产环境中,我们应该用什么方式(如 BPF Maps, Perf Buffers)将数据从内核传递到用户空间?
实验 3:炉火纯青 —— 使用 libbpf 和 XDP 实现高性能包过滤
目标:理解 XDP (eXpress Data Path) 的原理,并编写一个 C 语言的 XDP 程序来在网卡驱动层丢弃网络包。
工具:libbpf, Clang/LLVM, iproute2, C 语言。
步骤:
安装 libbpf-dev, clang, llvm。
编写一个 C 文件 (xdp_dropper.c),包含一个 XDP 程序。该程序的功能非常简单:直接返回 XDP_DROP,表示丢弃所有收到的包。
使用 Clang 将其编译成 BPF 字节码(.o 文件)。
找到你的网络接口名称(如 eth0)。
使用 iproute2 命令将你的 XDP 程序加载到网络接口上:sudo ip link set dev eth0 xdp obj xdp_dropper.o sec xdp。
尝试从另一台机器 ping 这个网络接口。
卸载程序:sudo ip link set dev eth0 xdp off。
验证与思考:
验证:加载 XDP 程序后,ping 是否超时?卸载后,ping 是否恢复正常?
思考:为什么 XDP 的性能远高于 iptables?XDP 程序在网络协议栈的哪一层执行?XDP_PASS, XDP_TX, XDP_REDIRECT 各有什么作用?
领域二:异步 I/O: io_uring
实验 1:牛刀小试 —— 使用 fio 对比 I/O 引擎性能
目标:直观感受 io_uring 相比传统异步 I/O (libaio) 的性能优势。
工具:fio (Flexible I/O Tester)。
步骤:
安装 fio:sudo apt install fio。
创建一个大的测试文件:fallocate -l 1G testfile.dat。
使用 libaio 引擎进行随机读测试:fio --name=aio-test --ioengine=libaio --iodepth=64 --rw=randread --bs=4k --size=1G --filename=testfile.dat。记录 IOPS 和延迟。
使用 io_uring 引擎进行同样的测试:fio --name=uring-test --ioengine=io_uring --iodepth=64 --rw=randread --bs=4k --size=1G --filename=testfile.dat。
对比两次测试的 IOPS (每秒 I/O 操作次数) 和延迟 (lat) 结果。
验证与思考:
验证:io_uring 的 IOPS 是否显著高于 libaio?延迟是否更低?
思考:io_uring 为何更快?思考一下系统调用的开销。io_uring 是如何减少系统调用次数的?(提示:SQ 和 CQ 环形缓冲区)。
实验 2:登堂入室 —— 使用 liburing 编写简单的文件拷贝程序
目标:学会使用 liburing 库来提交一个 I/O 请求并处理其完成事件。
工具:liburing, C 语言。
步骤:
安装 liburing-dev。
编写一个 C 程序,实现用 io_uring 将一个文件拷贝到另一个文件。
程序逻辑:初始化 io_uring -> 获取一个提交队列项 (SQE) -> 使用 io_uring_prep_read 准备读操作 -> 提交请求 -> 等待完成队列项 (CQE) -> 从 CQE 获取读操作结果 -> 准备并提交写操作 -> 等待完成 -> 清理退出。
验证与思考:
验证:程序运行后,目标文件内容是否与源文件完全一致?
思考:SQE 和 CQE 是什么?用户空间程序和内核是如何通过它们进行通信的?这个简单的实现是“一次读-等待-一次写”,如何改进才能让读和写并行起来,实现真正的流水线操作?
实验 3:融会贯通 —— 实现 I/O 请求链 (Linked SQEs)
目标:掌握 io_uring 的高级特性,将多个操作链接在一起,由内核按顺序执行,进一步减少用户态/内核态切换。
工具:liburing, C 语言。
步骤:
在实验 2 的基础上修改代码。
一次性准备两个 SQE:一个用于 read,一个用于 write。
在准备第一个(read)SQE 时,设置 IOSQE_IO_LINK 标志。
将这两个 SQE 一次性提交。内核会保证只有在 read 操作成功完成后,才会执行链接的 write 操作。
在循环中处理多个块的拷贝,每次都提交一个 read-write 链。
验证与思考:
验证:文件拷贝是否依然正确?使用 strace 观察,系统调用次数是否比实验 2 的朴素实现更少?
思考:IOSQE_IO_LINK 带来了什么好处?它与自己手动在用户态等待完成再提交下一个请求相比,优势在哪里?io_uring 还可以用于网络、fsync 等非文件 I/O 操作,你能想到哪些应用场景?
领域三:云原生基础:容器与虚拟化
实验 1:手动造轮 —— 使用 unshare 和 chroot 创建简易容器
目标:不使用 Docker,手动模拟容器的创建过程,深刻理解 Namespace 隔离。
工具:unshare, chroot, 一个 rootfs 目录 (如 alpine-minirootfs)。
步骤:
下载一个 Alpine Linux 的迷你根文件系统并解压到 ~/my-container。
运行命令:sudo unshare --fork --pid --mount-proc --mount -- sh -c "chroot ~/my-container /bin/sh"
在新启动的 shell 中,运行 ps aux。你看到了什么?
运行 hostname new-name,然后 hostname。
退出这个 shell,在外部再次运行 hostname。
验证与思考:
验证:在“容器”内,ps 是否只显示了 sh 和 ps 等极少数进程,且 sh 的 PID 是 1?修改的 hostname 是否只在容器内生效?
思考:这个简易容器和 Docker 容器还差了什么?(提示:网络隔离 net ns,用户隔离 user ns,资源限制 Cgroups)。
实验 2:资源铁笼 —— 使用 Cgroups V2 限制进程资源
目标:学会使用 Cgroups V2 接口来限制一个进程的 CPU 和内存使用。
工具:cgcreate, cgexec, 或直接操作 /sys/fs/cgroup 文件系统。
步骤:
创建一个新的 cgroup:sudo mkdir /sys/fs/cgroup/my-slice。
设置 CPU 上限:echo "10000 100000" | sudo tee /sys/fs/cgroup/my-slice/cpu.max (表示每 100ms 最多使用 10ms CPU,即 10%)。
设置内存上限:echo "100M" | sudo tee /sys/fs/cgroup/my-slice/memory.max。
编写一个消耗资源的脚本(如 while true; do :; done 消耗 CPU,或一个分配大量内存的 Python 脚本)。
将该脚本的 PID 写入 cgroup:echo $PID | sudo tee /sys/fs/cgroup/my-slice/cgroup.procs。
使用 top 或 htop 观察该进程的资源使用情况。
验证与思考:
验证:该进程的 CPU 使用率是否被限制在 10% 左右?内存消耗脚本是否在达到 100M 时被 OOM Killer 杀死?
思考:Cgroups V2 相比 V1 有哪些改进?除了 CPU 和内存,Cgroups 还能限制哪些资源?
实验 3:深入 KVM —— 编写最小的虚拟机监视器
目标:理解 KVM 的基本工作模式:通过 /dev/kvm 的 ioctl 来创建和管理虚拟机。
工具:C 语言, gcc。
步骤:
这是一个高难度实验,强烈建议寻找并阅读一个最小的 KVM 示例代码(搜索 "minimal KVM example")。
编写一个 C 程序,完成以下步骤: a. 打开 /dev/kvm。 b. 使用 KVM_CREATE_VM ioctl 创建一个虚拟机。 c. 为虚拟机分配一小块内存作为 Guest Memory,并使用 KVM_SET_USER_MEMORY_REGION 告知 KVM。 d. 在这块内存的开头写入一个单字节的机器码 0xf4 (HLT 指令)。 e. 使用 KVM_CREATE_VCPU 创建一个虚拟 CPU。 f. 使用 KVM_RUN ioctl 启动 vCPU。
检查 KVM_RUN 的返回值和 kvm_run 结构体中的 exit_reason。
验证与思考:
验证:KVM_RUN 返回后,exit_reason 是否为 KVM_EXIT_HLT?
思考:这个过程是如何工作的?什么是 VM-Exit?当 Guest OS 想要执行 I/O 操作时会发生什么?virtio 在其中扮演了什么角色?
以上计划为你提供了清晰的、逐步深入的实践路径。完成这些实验,你对这些热门领域的理解将远远超越只读书本的层面,真正达到“手中有码,心中有数”的境界。祝你实验顺利,探索愉快!
rgdb
A gdb write in Rust, Inspired By https://tartanllama.xyz/posts/writing-a-linux-debugger/setup/ .
my project: https://github.com/fkcrazy001/rgdb.gits
GOALS:
从文章中继承,后续看情况会不会新增
- Launch, halt, and continue execution
- Set breakpoints on
- Memory addresses
- Source code lines
- Function entry
- Read and write registers and memory
- Single stepping
- si
- s
- finish
- n
- Print current source location
- Print backtrace
- Print values of simple variables
and more todo:
- Remote debugging
- Shared library and dynamic loading support
- Expression evaluation
- Multi-threaded debugging support
SETUP
文章中说需要解析一下命令行参数和DWARF调试信息,原文中使用了 Linenoise 和 libelfin。 Rust中的话就用 clap 和 gimli 好了,都是主流库,而且在MAC上也有支持,所以进行这个开发会更方便。
- 启动: 先不支持 attach 到 pid
通过下面这种方式启动,那么启动阶段要先创建一下子进程,在子进程中来通过 ptrace 系统调用来让自己停下来先,等着父进程来调试自己。
rgdb $PROCESS <$ARGS>
通过封装好的 command::new 这种函数,直接来启动子进程会导致子进程可能退出了,而父进程都没有机会去控制它。
所以这里不能用这个函数,必须使用 nix 库的函数,手动 fork 和 execv 子进程, 然后在这中间插入 SIGTRAP 信号,让子进程停下来先。
#![allow(unused)]
fn main() {
// let sub_process = Command::new(prog.program).args(prog.args).spawn()?;
let pid = match unsafe { fork()? } {
ForkResult::Child => {
ptrace::traceme()?;
// traceme on some platform, like macos, doesn't send a signal
unsafe { raise(SIGTRAP) };
execv(&pn, &args)?;
unreachable!();
}
ForkResult::Parent { child } => child,
};
}- 设计 debugger
设计一个 debugger, 这个 debugger 首先要能够
- 接收用户输入
- 操作子进程
对于处理用户输入,gdb有搜索和自动补全的功能,rust有 rustyline 可以很方便的解决这个问题。
然后需要把这些输入一个个翻译为对应的subcommand, 然后执行对应的动作。
SUBCOMMAND 实现
continue
很简单,就是通过 ptrace::cont 来通知内核(可以带上一个信号)。
关于系统调用具体干了什么,可以查看 syscall专栏。
break point
有软件 break point 和 硬件 break point。
- 软件 break point
想法是这样的: 当break一个代码地址时,把这儿的指令改掉,比如说 改成 int 3(x86-64)上,这样执行到这儿就会陷入中断,linux 会执行 SIGTRAP 的逻辑。 这样父进程就能收到消息了。
- 硬件 break point
硬件断点利用处理器提供的调试寄存器来实现,不需要修改目标程序的指令。这在调试只读内存(如 ROM)或者设置数据断点(Watchpoint)时非常有用。
实现思路:
- x86-64: 使用
DR0-DR3调试寄存器存储断点地址,并通过DR7调试控制寄存器来启用它们。在 Linux 中,可以通过ptrace(PTRACE_POKEUSER, ...)来设置这些寄存器,偏移量通常由libc或nix提供。 - AArch64: 使用
DBGBVR<n>_EL1(Breakpoint Value Registers) 和DBGBCR<n>_EL1(Breakpoint Control Registers)。在 Linux 中,通常通过ptrace(PTRACE_SETREGSET, ...)配合NT_ARM_HW_BREAK寄存器集类型来配置。
限制:
- 硬件断点的数量有限(x86 通常为 4 个,ARM 通常为 2-16 个)。
- 设置硬件断点不涉及内存修改,因此不会破坏指令缓存。
register
为了观察和修改程序的状态,我们需要读写 CPU 寄存器的能力。
在 Linux 上,我们可以通过 ptrace(PTRACE_GETREGS, ...) 一次性获取所有的通用寄存器。
- 对于 x86_64,这会返回
user_regs_struct,包含了rax,rbx,rip,rsp等。 - 对于 AArch64,通常使用
PTRACE_GETREGSET并指定NT_PRSTATUS来获取寄存器信息。
一旦获取了寄存器结构体,我们就可以:
- read: 打印指定寄存器的值,或者打印全部寄存器。
- write: 修改指定寄存器的值,然后通过
PTRACE_SETREGS写回。
memory
除了寄存器,观察进程内存也至关重要。
- read: 使用
ptrace(PTRACE_PEEKDATA, ...)读取指定地址的内存。由于这个系统调用每次只读取一个字(word),我们需要循环调用来读取大块内存。 - write: 使用
ptrace(PTRACE_POKEDATA, ...)向指定地址写入数据。这同样是按字操作的。在写入断点(软件断点)时,我们实际上就是在进行内存写入。
ELF and DWARF (Step 4)
为了让调试器理解源代码,我们需要解析二进制文件中的调试信息。
ELF 解析
使用 object 库来解析 ELF 文件结构。主要用于查找符号表(Symbol Table)以及定位 DWARF 相关的 Section(如 .debug_info, .debug_line)。
DWARF 解析
使用 gimli 库来处理 DWARF 格式。
- 行表 (Line Table): 用于机器码地址与源代码行号之间的映射。
- 编译单元 (Compilation Units): 调试信息的顶层结构。
- 加载地址处理: 对于 PIE (Position Independent Executables),调试信息中的地址是相对偏移。我们需要通过
/proc/<pid>/maps获取进程的加载基址,并将绝对地址转换为相对偏移后再进行 DWARF 查找。
调试信息查找路径
为了与 GDB 行为一致,rgdb 会按以下顺序查找调试信息:
- 二进制文件自身的 Section。
- 同目录下的
.debug文件。 - 系统全局调试路径
/usr/lib/debug/。
Source and Signals (Step 5)
增强了信号处理、源代码显示,以及 REPL 的退出体验,提升调试“可用性”。
信号处理
在 handle_wait_status 中,增加了对进程状态的全面处理:
- Stopped: 处理由信号(如
SIGTRAP,SIGSEGV等)引起的停止。 - Exited: 捕获进程正常退出的状态及退出码。
- Signaled: 捕获进程被信号终止的情况。
当捕获到 Exited/Signaled 时,会标记 inferior 已退出,REPL 会自动结束(不需要手动 q)。
源码上下文显示
当程序在带有调试信息的地址停止时,rgdb 会自动:
- 定位源码: 通过 DWARF 信息找到对应的文件和行号。
- 显示代码: 读取源码文件并打印当前行及其前后各 3 行的上下文。
- 高亮当前行: 使用
=>标记当前正在执行的行。
断点位置的地址校正
在 x86_64 上,执行到 int3(0xCC)后 CPU 会把 RIP 停在 “断点地址 + 1”。因此在展示源码和做行号映射时,rgdb 会对 SIGTRAP 做 pc-1 的校正,从而把“当前停止位置”显示成正确的源码行。
历史记录的健壮性
rustyline 会尝试读取/写入 .rgdb_history。在 sudo 调试、或文件权限变化的情况下,保存历史记录可能失败。为了避免退出时因为历史记录保存失败导致程序报错,保存失败会被忽略。
Source-Level Stepping (Step 6)
实现了基于源代码的单步执行命令。
指令级单步 (si)
使用 ptrace(PTRACE_SINGLESTEP, ...) 执行下一条机器码指令。如果当前位于断点位置,会自动处理断点的跳过和恢复。
源码级单步 (s)
执行代码直到源代码的行号发生变化。底层通过循环执行 si 并比对 DWARF 行表信息实现。如果进入了子函数且子函数有调试信息,会停在子函数的第一行。
源码级跳过 (n)
rgdb 的 n 不再简单地“循环 single-step 直到行号变化”。实际实现采用了更接近 gdb 的策略:用 DWARF 行表找出“下一行语句”的地址,然后设置临时断点并 continue 过去。
核心流程:
- 确定当前行:从当前
PC映射到SourceLocation(file,line,column)。 - 查找下一行地址:遍历
.debug_line的行表,寻找满足条件的下一条 row:- 与当前文件匹配(支持 basename 末尾匹配)
row.is_stmt()为真(过滤掉非语句点)row.line > current_line且row.address > current_pc_offset
- 设置临时断点:在下一行地址插入断点(temporary breakpoint)。
- continue 执行:进程运行到临时断点时停止。
- 清理临时断点:跨过断点时自动恢复原指令,并从断点表中移除该断点。
当当前行已经是函数最后一行、行表找不到“下一行”时,n 会直接 continue 直到进程退出,从而避免“跳进运行时/库代码后停在奇怪地址”的体验。
退出当前函数 (finish)
继续执行直到当前函数返回。
- x86_64: 通过读取
RSP指向的栈顶获取返回地址,并设置临时断点。 - AArch64: 通过读取
LR(X30) 寄存器获取返回地址,并设置临时断点。
Source-Level Breakpoints (Step 7)
支持通过源代码层面的标识符设置断点。
地址断点
支持原始的十六进制地址断点。
gdb> break 0x40114e
函数名断点
支持通过函数名称设置断点。实现上会遍历 DWARF 的 DW_TAG_subprogram,找到匹配 DW_AT_name 的条目,并读取 DW_AT_low_pc 作为函数入口。
为了让断点更“像 gdb”,rgdb 不一定把断点打在函数序言(prologue)的位置,而是尽量定位到函数体内第一条可执行语句(first statement):
- 先取到
low_pc对应的源码行; - 再用行表找到该行之后的下一条语句地址;
- 把断点打在那条语句的地址上(这样
b main; c更容易停在int i = 0;而不是{)。
gdb> break main
文件:行号断点
支持通过 文件名:行号 的方式设置断点。实现上遍历 DWARF 行表(.debug_line)找到匹配行号且文件名匹配的 row,并把 row.address 转换为运行时地址。
gdb> break main.c:12
PIE/非 PIE 的地址换算
rgdb 会检测 ELF 类型:PIE(ET_DYN)需要根据 /proc/<pid>/maps 的加载基址做地址重定位;非 PIE(ET_EXEC)则使用绝对地址(不额外加基址),避免出现 b main 计算出错误地址导致 ptrace::read 返回 EIO 的问题。
Stack Unwinding (Step 8)
实现了函数调用栈的回溯功能 (backtrace/bt)。
帧指针回溯(Frame Pointer Unwinding)
当前实现采用基于帧指针链的简单回溯算法(对使用 -fno-omit-frame-pointer 编译的程序最可靠):
- 获取当前状态:读取
PC与帧指针RBP(x86_64)或X29(AArch64)。 - 函数名解析:优先通过 DWARF 的
DW_TAG_subprogram做地址范围匹配,打印func+0xoffset;如果 DWARF 不可用则尽量用符号表兜底(仅限当前可执行文件)。 - 源码行映射:用行表把
PC映射回file:line:column。 - 沿 FP 链向上走:
- x86_64:
[RBP]是上一帧RBP,[RBP+8]是返回地址 - AArch64:
[FP]是上一帧FP,[FP+8]是返回地址(对应 LR 保存位)
- x86_64:
- 终止条件:帧指针为 0、读取失败或超过最大深度(50)。
另外,为了避免在断点处把 PC 打印成 “地址+1”,回溯的第 0 帧会在检测到当前停在断点后做一次 pc-1 的修正。
Handling Variables (Step 9)
实现了读取并打印源代码变量值的功能。
变量查找
- 获取当前作用域: 根据当前的
PC指针,在 DWARF 信息中定位当前的子程序(Subprogram)。 - 名称匹配: 在当前子程序的作用域内,查找匹配给定名称的
DW_TAG_variable或DW_TAG_formal_parameter标签。 - 位置评估: 解析变量的
DW_AT_location属性。
变量位置求值(简化版)
为了保证稳定性,rgdb 目前实现了对常见 location expression 的直接求值(而不是尝试完整覆盖所有 DWARF 表达式):
- DW_OP_fbreg(栈上变量):会读取
DW_AT_frame_base(本项目里常见的是DW_OP_call_frame_cfa),并用简化的 CFA 计算来定位变量地址,然后ptrace读取内存。 - 寄存器变量:如果 location 表示寄存器,会直接读取对应寄存器值。
- 绝对地址:如果 location 给出地址,会直接读取该地址处的内存。
类型大小推导
为了避免把栈上相邻变量“读进来”,rgdb 会读取 DW_AT_type,沿着类型引用链查找 DW_AT_byte_size,从而确定读取的字节数(例如 int 读取 4 字节)。
gdb> p i
0x0
Advanced Topics (Step 10)
本阶段探索了一些高级调试技术,主要包括对符号表(Symbol Table)的支持。
符号表支持 (ELF Symbols)
即使二进制文件被剥离(stripped)了 DWARF 调试信息,或者在调试某些系统库时,我们仍然可以通过 ELF 符号表来设置断点。
- 加载符号: 在初始化时使用
object库解析 ELF 的.symtab或.dynsym段。 - 符号查找: 实现了
lookup_symbol,允许用户通过导出的符号名称进行断点设置。 - 加载地址适配: 与 DWARF 映射一致,符号地址也会根据进程的加载基址(Load Address)进行动态偏移计算。
目前符号表解析仅覆盖当前可执行文件。共享库(例如 libc)符号解析属于后续增强项(需要遍历 /proc/<pid>/maps 并解析每个映射的 ELF)。
gdb> break malloc
# 即使没有源码,也能在库函数入口设置断点
syscall
在linux上的各种 syscall 的机制研究,如果复杂的syscall,会另开专题来研究。
PTRACE 系统调用
https://man7.org/linux/man-pages/man2/ptrace.2.html
long ptrace(enum __ptrace_request op, pid_t pid,
void *addr, void *data);
每一个 op 都有不同的意思,所以对每一个op进行查看。
tracee: 被trace的对象,永远是一个线程。
tracer: trace 发起者。
PTRACE_TRACEME
文档上是这么说的: tracee(calling thread) 在 fork 之后可以执行这个系统调用,这样会置位可被TRACE的标志。还特意提到了,这个不会中断子进程的执行。
这和网上很多文档说的不一致,分析一下源码 (linux v6.19.6)。
kernel/ptrace.c: SYSCALL_DEFINE4(ptrace, long, request, long, pid, unsigned long, addr, unsigned long, data)
=> ptrace_traceme(void): current->ptrace = PT_PTRACED; // 这里就是设置了这个标志
// 尝试查看哪些地方用了 这个 flag,最终找到这样一条调用链
sys_execv => fs/exec.c: do_execveat_common => bprm_execve => exec_binprm
=> ptrace_event(PTRACE_EVENT_EXEC) {
if ((current->ptrace & (PT_PTRACED|PT_SEIZED)) == PT_PTRACED)
send_sig(SIGTRAP, current, 0);
}
// 系统调用返回到用户态之前,会去检查信号,在被 TRACE 情况下, 所有信号都会导致子进程被挂起(除了sig kill)。
// 代码在 signal.c: get_signal 函数中。
后续在文档中发现,ptrace有一个名为 PTRACE_O_TRACEEXEC 的option,新的gdb都应该用这个option。 所以网上很多的文档反而是描述了老的行为。man文档中推荐的才是较为新的且好的操作。
If the PTRACE_O_TRACEEXEC option is not in effect, all successful
calls to execve(2) by the traced process will cause it to be sent
a SIGTRAP signal, giving the parent a chance to gain control
before the new program begins execution.
PTRACE_CONT
Restart the stopped tracee process. If data is nonzero, it
is interpreted as the number of a signal to be delivered to
the tracee; otherwise, no signal is delivered. Thus, for
example, the tracer can control whether a signal sent to
the tracee is delivered or not. (addr is ignored.)
紧接着上面的子进程被挂起之后,发送 cont 会让子进程被唤醒,
并且唤醒理由放在 exit_code 中(ptrace_resume 函数中),会被翻译为signal继续去执行子进程的信号处理流程。
PTRACE_SINGLESTEP
单步执行下一条指令。对于 si 这种“指令级步进”,底层就是循环:
ptrace(PTRACE_SINGLESTEP, pid, 0, sig)waitpid(pid, ...)等待 tracee 因为单步陷入而停止(通常是SIGTRAP)
内核侧主要路径(不同版本/架构细节会有差异):
kernel/ptrace.c: SYSCALL_DEFINE4(ptrace, ...) => ptrace_request(...)
case PTRACE_SINGLESTEP:
ptrace_resume(child, request, data);
-> user_enable_single_step(child);
-> wake_up_state(child, __TASK_TRACED/ TASK_RUNNING ...);
user_enable_single_step 是架构相关的入口:x86_64 通常依赖 TF/trap flag,arm64 走对应的单步机制。
PTRACE_GETREGS / PTRACE_SETREGS
读写“通用寄存器快照”。在 gdb 中对应 register read/write 子命令。
用户态调用模型:
- tracee 停在 traced-stop(一般来自断点/单步/信号)
- tracer
PTRACE_GETREGS拉取寄存器结构体 - 如需修改,改完后
PTRACE_SETREGS写回 PTRACE_CONT/PTRACE_SINGLESTEP继续运行
内核侧主要路径:
kernel/ptrace.c: SYSCALL_DEFINE4(ptrace, ...) => ptrace_request(...)
case PTRACE_GETREGS:
case PTRACE_SETREGS:
arch_ptrace(request, child, addr, data);
寄存器格式是架构相关的:x86_64 是 user_regs_struct;arm64 更推荐用 GETREGSET/SETREGSET(见下)。
PTRACE_GETREGSET / PTRACE_SETREGSET
更通用/可扩展的寄存器访问接口,配合 addr = (void*)NT_* 指定寄存器集类型,data 指向 struct iovec。
在 gdb 里常见的用法:
NT_PRSTATUS:通用寄存器(含 PC/SP 等)NT_ARM_HW_BREAK:arm64 硬件断点寄存器集
用户态调用模型:
- 准备
iovec { .iov_base = buf, .iov_len = len } ptrace(PTRACE_GETREGSET, pid, NT_PRSTATUS, &iov)读取- 修改
buf后ptrace(PTRACE_SETREGSET, pid, NT_PRSTATUS, &iov)写回
内核侧主要路径(抽象层次):
kernel/ptrace.c: SYSCALL_DEFINE4(ptrace, ...) => ptrace_request(...)
case PTRACE_GETREGSET:
case PTRACE_SETREGSET:
ptrace_regset(child, request, addr /* NT_* */, data /* iovec */);
-> regset = task_user_regset_view(child)->regsets[...]
-> regset->get()/set()
PTRACE_PEEKDATA / PTRACE_POKEDATA
按“一个 machine word”读写 tracee 的虚拟内存,是软件断点(写 int3/0xCC)和 memory read/write 的基础。
用户态调用模型:
word = ptrace(PTRACE_PEEKDATA, pid, addr, 0)读取- 修改目标字节(例如把最低字节改成
0xCC) ptrace(PTRACE_POKEDATA, pid, addr, word)写回
内核侧主要路径(抽象层次):
kernel/ptrace.c: SYSCALL_DEFINE4(ptrace, ...) => ptrace_request(...)
case PTRACE_PEEKDATA:
case PTRACE_POKEDATA:
ptrace_peekdata/ptrace_pokedata(...)
-> access_process_vm(child, addr, buf, len, flags);
常见现象:
- 地址无效/不可访问时,容易在用户态看到
EIO - 软件断点触发时,x86_64 的
RIP会停在 “断点地址 + 1”,所以调试器一般要做pc-1校正
PTRACE_POKEUSER
写 tracee 的 “user area” 中的字段(不同架构含义不同)。在 gdb 的硬件断点实现里,x86_64 常用它来写 DR0-DR3/DR7 这样的调试寄存器映射。
内核侧主要路径(抽象层次):
kernel/ptrace.c: SYSCALL_DEFINE4(ptrace, ...) => ptrace_request(...)
case PTRACE_POKEUSER:
arch_ptrace(request, child, addr, data);
是否允许写、写到哪里、如何落到真实硬件寄存器,基本都在架构代码里做校验与转换。
虚拟化技术
QEMU TCG 代码翻译技术研究
想研究下QEMU的TCG技术,主要是以下几点:
- QEMU地址模型(CPU访问地址时如何通过softmmu进行地址转换)
- QEMU指令翻译(如何定义新指令、TCG指令实现、TCG如何翻译为host machine code)
- TCG的ISA和寄存器映射规范
1. QEMU 地址模型与 SoftMMU
1.1 整体架构
QEMU在系统模式(system emulation)下使用软件MMU来实现虚拟地址到物理地址的转换。这个过程主要在 accel/tcg/cputlb.c 中实现。
// cputlb.c:127-140
// Find the TLB index corresponding to the mmu_idx + address pair.
static inline uintptr_t tlb_index(CPUState *cpu, uintptr_t mmu_idx,
vaddr addr)
{
uintptr_t size_mask = cpu_tlb_fast(cpu, mmu_idx)->mask >> CPU_TLB_ENTRY_BITS;
return (addr >> TARGET_PAGE_BITS) & size_mask;
}
// Find the TLB entry corresponding to the mmu_idx + address pair.
static inline CPUTLBEntry *tlb_entry(CPUState *cpu, uintptr_t mmu_idx,
vaddr addr)
{
return &cpu_tlb_fast(cpu, mmu_idx)->table[tlb_index(cpu, mmu_idx, addr)];
}
1.2 地址转换流程
当guest CPU访问内存时,流程如下:
Guest VA -> TLB lookup -> (命中) -> Host VA
|
+-> (未命中) -> MMU仿真代码 -> 更新TLB -> 重试
关键数据结构在 tcg/tcg-op-ldst.c 中定义的 qemu_ld 和 qemu_st 操作:
// tcg-op-ldst.c:241-283
void tcg_gen_qemu_ld_i32_chk(TCGv_i32 val, TCGTemp *addr, TCGArg idx,
MemOp memop, TCGType addr_type)
{
tcg_debug_assert(addr_type == tcg_ctx->addr_type);
tcg_debug_assert((memop & MO_SIZE) <= MO_32);
tcg_gen_qemu_ld_i32_int(val, addr, idx, memop);
}
static void tcg_gen_qemu_ld_i32_int(TCGv_i32 val, TCGTemp *addr,
TCGArg idx, MemOp memop)
{
MemOp orig_memop;
MemOpIdx orig_oi, oi;
TCGv_i64 copy_addr;
TCGTemp *addr_new;
tcg_gen_req_mo(TCG_MO_LD_LD | TCG_MO_ST_LD);
orig_memop = memop = tcg_canonicalize_memop(memop, 0, 0);
orig_oi = oi = make_memop_idx(memop, idx);
// 字节序转换处理
if ((memop & MO_BSWAP) && !tcg_target_has_memory_bswap(memop)) {
memop &= ~MO_BSWAP;
oi = make_memop_idx(memop, idx);
}
addr_new = tci_extend_addr(addr);
copy_addr = plugin_maybe_preserve_addr(addr);
gen_ldst1(INDEX_op_qemu_ld, TCG_TYPE_I32, tcgv_i32_temp(val), addr_new, oi);
// ...
}
1.3 TLB 结构设计
TLB使用直接映射(direct-mapped)的方式,核心结构:
// cputlb.c:95-103
static inline size_t tlb_n_entries(CPUTLBDescFast *fast)
{
return (fast->mask >> CPU_TLB_ENTRY_BITS) + 1;
}
static inline size_t sizeof_tlb(CPUTLBDescFast *fast)
{
return fast->mask + (1 << CPU_TLB_ENTRY_BITS);
}
每个TLB entry包含:
addr_read/addr_write/addr_code: 不同访问类型的地址addend: 地址偏移量(guest VA -> host VA)phys_addr: 物理地址(可选)
2. QEMU 指令翻译机制
2.1 翻译流程概览
整体翻译流程在 accel/tcg/translator.c 中:
// translator.c:122-150
void translator_loop(CPUState *cpu, TranslationBlock *tb, int *max_insns,
vaddr pc, void *host_pc, const TranslatorOps *ops,
DisasContextBase *db)
{
uint32_t cflags = tb_cflags(tb);
TCGOp *icount_start_insn;
TCGOp *first_insn_start = NULL;
bool plugin_enabled;
// 初始化DisasContext
db->tb = tb;
db->pc_first = pc;
db->pc_next = pc;
db->is_jmp = DISAS_NEXT;
db->num_insns = 0;
db->max_insns = *max_insns;
db->insn_start = NULL;
db->fake_insn = false;
db->host_addr[0] = host_pc;
db->host_addr[1] = NULL;
db->record_start = 0;
db->record_len = 0;
db->code_mmuidx = cpu_mmu_index(cpu, true);
ops->init_disas_context(db, cpu);
// 开始翻译
icount_start_insn = gen_tb_start(db, cflags);
// ...
}
2.2 TCG opcode 定义
TCG指令定义在 include/tcg/tcg-opc.h:
// include/tcg/tcg-opc.h:29-94
/* predefined ops */
DEF(discard, 1, 0, 0, TCG_OPF_NOT_PRESENT)
DEF(set_label, 0, 0, 1, TCG_OPF_BB_END | TCG_OPF_NOT_PRESENT)
/* variable number of parameters */
DEF(call, 0, 0, 3, TCG_OPF_CALL_CLOBBER | TCG_OPF_NOT_PRESENT)
DEF(br, 0, 0, 1, TCG_OPF_BB_END | TCG_OPF_NOT_PRESENT)
DEF(brcond, 0, 2, 2, TCG_OPF_BB_END | TCG_OPF_COND_BRANCH | TCG_OPF_INT)
DEF(mov, 1, 1, 0, TCG_OPF_INT | TCG_OPF_NOT_PRESENT)
DEF(add, 1, 2, 0, TCG_OPF_INT)
DEF(and, 1, 2, 0, TCG_OPF_INT)
DEF(sub, 1, 2, 0, TCG_OPF_INT)
DEF(xor, 1, 2, 0, TCG_OPF_INT)
// ... 更多算术逻辑操作
DEF(ld8u, 1, 1, 1, TCG_OPF_INT) // load unsigned byte
DEF(ld8s, 1, 1, 1, TCG_OPF_INT) // load signed byte
DEF(ld16u, 1, 1, 1, TCG_OPF_INT) // load unsigned halfword
DEF(ld16s, 1, 1, 1, TCG_OPF_INT) // load signed halfword
DEF(st8, 0, 2, 1, TCG_OPF_INT) // store byte
DEF(st16, 0, 2, 1, TCG_OPF_INT) // store halfword
DEF(qemu_ld, 1, 1, 1, TCG_OPF_CALL_CLOBBER | TCG_OPF_SIDE_EFFECTS | TCG_OPF_INT)
DEF(qemu_st, 0, 2, 1, TCG_OPF_CALL_CLOBBER | TCG_OPF_SIDE_EFFECTS | TCG_OPF_INT)
DEF宏的参数说明:
// DEF(name, oargs, iargs, cargs, flags)
// - name: 指令名称
// - oargs: 输出参数个数
// - iargs: 输入参数个数
// - cargs: 常量参数个数
// - flags: 标志位
2.3 如何定义新指令
以RISC-V的 lui 指令为例,展示如何定义和翻译新指令:
// target/riscv/tcg/translator-rvi.c.inc
static bool trans_lui(DisasContext *ctx, arg_lui *a)
{
gen_set_gpr(ctx, a->rd, a->imm);
return true;
}
lui 指令将20位立即数加载到寄存器的高位。翻译过程:
- 解码阶段:从guest二进制中提取指令操作码和操作数
- 翻译阶段:调用
trans_lui函数 - TCG IR生成:调用
gen_set_gpr生成TCG指令
// 实际生成的TCG IR伪代码:
// mov_i32 t0, $imm20 (将立即数放入临时寄存器)
// deposit_i32 t0, t0, $0, 12 (将立即数移到高位)
// mov_i64 x[rd], t0 (写回目标寄存器)
2.4 TCG 指令操作API
TCG提供多种指令生成函数(位于 tcg/tcg-op.c):
// tcg-op.c:40-105
TCGOp * NI tcg_gen_op1(TCGOpcode opc, TCGType type, TCGArg a1)
{
TCGOp *op = tcg_emit_op(opc, 1);
TCGOP_TYPE(op) = type;
op->args[0] = a1;
return op;
}
TCGOp * NI tcg_gen_op2(TCGOpcode opc, TCGType type, TCGArg a1, TCGArg a2)
{
TCGOp *op = tcg_emit_op(opc, 2);
TCGOP_TYPE(op) = type;
op->args[0] = a1;
op->args[1] = a2;
return op;
}
TCGOp * NI tcg_gen_op3(TCGOpcode opc, TCGType type, TCGArg a1,
TCGArg a2, TCGArg a3)
{
TCGOp *op = tcg_emit_op(opc, 3);
TCGOP_TYPE(op) = type;
op->args[0] = a1;
op->args[1] = a2;
op->args[2] = a3;
return op;
}
类型安全的包装器:
// tcg-op.c:117-180
static void DNI tcg_gen_op2_i32(TCGOpcode opc, TCGv_i32 a1, TCGv_i32 a2)
{
tcg_gen_op2(opc, TCG_TYPE_I32, tcgv_i32_arg(a1), tcgv_i32_arg(a2));
}
static void DNI tcg_gen_op2_i64(TCGOpcode opc, TCGv_i64 a1, TCGv_i64 a2)
{
tcg_gen_op2(opc, TCG_TYPE_I64, tcgv_i64_arg(a1), tcgv_i64_arg(a2));
}
static void DNI tcg_gen_add_i32(TCGv_i32 ret, TCGv_i32 a, TCGv_i32 b)
{
tcg_gen_op2_i32(INDEX_op_add, ret, a, b);
}
3. TCG 到 Host Code 的翻译
3.1 Target Backend 架构
每个host架构有自己的backend,位于 tcg/<arch>/ 目录。以x86_64为例:
// tcg/x86_64/tcg-target.h:30-80
#define TCG_TARGET_NB_REGS 32
typedef enum {
TCG_REG_EAX = 0,
TCG_REG_ECX,
TCG_REG_EDX,
TCG_REG_EBX,
TCG_REG_ESP,
TCG_REG_EBP,
TCG_REG_ESI,
TCG_REG_EDI,
TCG_REG_R8,
TCG_REG_R9,
TCG_REG_R10,
TCG_REG_R11,
TCG_REG_R12,
TCG_REG_R13,
TCG_REG_R14,
TCG_REG_R15,
TCG_REG_XMM0,
TCG_REG_XMM1,
TCG_REG_XMM2,
TCG_REG_XMM3,
TCG_REG_XMM4,
TCG_REG_XMM5,
TCG_REG_XMM6,
TCG_REG_XMM7,
TCG_REG_XMM8,
TCG_REG_XMM9,
TCG_REG_XMM10,
TCG_REG_XMM11,
TCG_REG_XMM12,
TCG_REG_XMM13,
TCG_REG_XMM14,
TCG_REG_XMM15,
TCG_REG_RAX = TCG_REG_EAX,
TCG_REG_RCX = TCG_REG_ECX,
TCG_REG_RDX = TCG_REG_EDX,
TCG_REG_RBX = TCG_REG_EBX,
TCG_REG_RSP = TCG_REG_ESP,
TCG_REG_RBP = TCG_REG_EBP,
TCG_REG_RSI = TCG_REG_ESI,
TCG_REG_RDI = TCG_REG_EDI,
TCG_AREG0 = TCG_REG_EBP,
TCG_REG_CALL_STACK = TCG_REG_ESP
} TCGReg;
3.2 寄存器分配策略
TCG使用复杂的寄存器分配算法,x86_64的分配顺序:
// tcg/x86_64/tcg-target.c.inc:52-88
static const int tcg_target_reg_alloc_order[] = {
TCG_REG_RBP,
TCG_REG_RBX,
TCG_REG_R12,
TCG_REG_R13,
TCG_REG_R14,
TCG_REG_R15,
TCG_REG_R10,
TCG_REG_R11,
TCG_REG_R9,
TCG_REG_R8,
TCG_REG_RCX,
TCG_REG_RDX,
TCG_REG_RSI,
TCG_REG_RDI,
TCG_REG_RAX,
TCG_REG_XMM0,
TCG_REG_XMM1,
// ... 更多XMM寄存器
};
分配原则:
- callee-saved寄存器优先(RBX, RBP, R12-R15)
- caller-saved寄存器次之(RAX, RCX, RDX等)
- 向量寄存器单独分配
3.3 TCG IR 到 Host 汇编的翻译
以 add 指令为例,查看x86_64后端如何实现:
// 伪代码展示翻译过程
TCG IR: add_i32 t0, t1, t2
↓
x86_64后端选择:
mov eax, [t1寄存器或内存]
add eax, [t2寄存器或内存]
mov [t0位置], eax
函数调用约定定义:
// tcg/x86_64/tcg-target.c.inc:92-120
static const int tcg_target_call_iarg_regs[] = {
#if defined(_WIN64)
TCG_REG_RCX,
TCG_REG_RDX,
#else
TCG_REG_RDI,
TCG_REG_RSI,
TCG_REG_RDX,
TCG_REG_RCX,
#endif
TCG_REG_R8,
TCG_REG_R9,
};
static TCGReg tcg_target_call_oarg_reg(TCGCallReturnKind kind, int slot)
{
switch (kind) {
case TCG_CALL_RET_NORMAL:
tcg_debug_assert(slot >= 0 && slot <= 1);
return slot ? TCG_REG_EDX : TCG_REG_EAX;
// ...
}
}
3.4 TCG类型系统
TCG定义多种数据类型:
// include/tcg/tcg.h:128-149
typedef enum TCGType {
TCG_TYPE_I32, // 32位整数
TCG_TYPE_I64, // 64位整数
TCG_TYPE_I128, // 128位整数
TCG_TYPE_V64, // 64位向量
TCG_TYPE_V128, // 128位向量
TCG_TYPE_V256, // 256位向量
/* 别名 */
TCG_TYPE_REG = TCG_TYPE_I64, // 主机寄存器大小
TCG_TYPE_PTR, // 指针大小
} TCGType;
4. Translation Block (TB) 机制
4.1 TB 结构和链接
// accel/tcg/translate-all.c:41-100
TBContext tb_ctx;
static int encode_search(TranslationBlock *tb, uint8_t *block)
{
uint8_t *highwater = tcg_ctx->code_gen_highwater;
uint64_t *insn_data = tcg_ctx->gen_insn_data;
uint16_t *insn_end_off = tcg_ctx->gen_insn_end_off;
uint8_t *p = block;
int i, j, n;
for (i = 0, n = tb->icount; i < n; ++i) {
// 编码每条指令的信息
for (j = 0; j < INSN_START_WORDS; ++j) {
uint64_t prev = (i == 0 ? 0 : insn_data[(i - 1) * INSN_START_WORDS + j]);
uint64_t curr = insn_data[i * INSN_START_WORDS + j];
p = encode_sleb128(p, curr - prev);
}
// ...
}
return p - block;
}
4.2 TB 链接优化
// docs/devel/tcg.rst:52-110
/*
* 直接块链链接(Direct Block Chaining)
*
* 优化前:每次执行完TB都要回到main loop查找下一个TB
* 优化后:相邻TB之间直接跳转,避免回main loop
*/
// 关键函数
tcg_gen_goto_tb() // 发出goto_tb TCG指令
tcg_gen_exit_tb() // 退出当前TB
tcg_gen_lookup_and_goto_ptr() // 查找并跳转到目标TB
4.3 TB 执行流程
+------------------+
| CPU执行入口 |
| cpu_exec() |
+--------+---------+
|
v
+--------+---------+
| 查找TB缓存 |
| tb_jmp_cache |
+--------+---------+
|
[命中] [未命中]
| |
v v
+--------+ +--------+
| 执行TB | | 翻译guest |
| 代码 | | 指令 |
+--------+ +--------+
| |
+----->--------+
| 生成TCG IR |
+--------+
| 优化 |
+--------+
| 汇编 |
+--------+
| 缓存TB |
+--------+
5. 具体实例:ADD指令翻译全过程
5.1 Guest代码
# RISC-V: add x3, x1, x2
# 功能: x3 = x1 + x2
5.2 TCG IR生成
// 翻译器生成以下TCG指令序列:
tcg_gen_add_i64(tmp0, cpu_x[1], cpu_x[2]); // tmp0 = x1 + x2
tcg_gen_mov_i64(cpu_x[3], tmp0); // x3 = tmp0
tcg_gen_exit_tb(tb, TB_EXIT_REQUESTED); // 退出TB
5.3 汇编优化后
# x86_64优化后的代码 (伪代码)
mov rax, QWORD PTR [rbp + x1_offset] ; 加载x1
add rax, QWORD PTR [rbp + x2_offset] ; 加上x2
mov QWORD PTR [rbp + x3_offset], rax ; 保存x3
jmp next_tb_address ; 跳转到下一个TB
5.4 内存访问路径
TCG虚拟寄存器(cpu_x[1])
↓
映射到host寄存器或内存位置
↓
通过softmmu访问实际内存
↓
TLB查找 → 地址转换 → Host访问
6. 实践:添加自定义指令
6.1 步骤概述
- 在target翻译器中添加decode函数
- *定义trans_函数生成TCG IR
- 注册到指令解码表
6.2 代码示例
// 1. 在target/riscv/insn_trans/trans_xxx.c.inc中添加
static bool trans_my_custom_op(DisasContext *ctx, arg_my_custom_op *a)
{
TCGv temp = tcg_temp_new();
TCGv result = tcg_temp_new();
// 生成TCG IR
tcg_gen_andi_i64(temp, get_gpr(ctx, a->rs1), a->mask); // temp = rs1 & mask
tcg_gen_shri_i64(temp, temp, a->shift); // temp >>= shift
tcg_gen_andi_i64(result, temp, a->width - 1); // result = temp & (width-1)
// 写回结果
gen_set_gpr(ctx, a->rd, result);
// 释放临时寄存器
tcg_temp_free(temp);
tcg_temp_free(result);
return true;
}
// 2. 在decode函数中调用
// decode_my_custom_op() -> trans_my_custom_op()
6.3 注意事项
- 性能考虑: 复杂指令用helper函数实现更高效
- 异常处理: 需要处理非法指令和特权级异常
- 原子性: 多线程环境下需考虑内存屏障
7. QEMU 中断/异常机制
7.1 整体架构
QEMU的中断/异常处理机制是模拟guest CPU的核心功能之一。它需要处理两种场景:
- Guest内部异常:指令执行过程中触发的异常(如非法指令、页面错误)
- 外部中断:来自外设的中断信号(如定时器、I/O设备)
核心处理流程在 accel/tcg/cpu-exec.c 中实现:
// cpu-exec.c:701-750
if (cpu->exception_index >= EXCP_INTERRUPT) {
/* exit request from the cpu execution loop */
*ret = cpu->exception_index;
if (*ret == EXCP_DEBUG) {
cpu_handle_debug_exception(cpu);
}
cpu->exception_index = -1;
return true;
}
#ifndef CONFIG_USER_ONLY
if (replay_exception()) {
const TCGCPUOps *tcg_ops = cpu->cc->tcg_ops;
bql_lock();
tcg_ops->do_interrupt(cpu); // 调用架构特定的中断处理
bql_unlock();
cpu->exception_index = -1;
// ...
}
#endif
7.2 Guest指令触发的异常
7.2.1 异常分类
以RISC-V为例,异常类型定义在 target/riscv/cpu_bits.h:
// target/riscv/cpu_bits.h:761-786
typedef enum RISCVException {
RISCV_EXCP_NONE = -1, /* sentinel value */
RISCV_EXCP_INST_ADDR_MIS = 0x0, // 指令地址未对齐
RISCV_EXCP_INST_ACCESS_FAULT = 0x1, // 指令访问错误
RISCV_EXCP_ILLEGAL_INST = 0x2, // 非法指令
RISCV_EXCP_BREAKPOINT = 0x3, // 断点
RISCV_EXCP_LOAD_ADDR_MIS = 0x4, // 加载地址未对齐
RISCV_EXCP_LOAD_ACCESS_FAULT = 0x5, // 加载访问错误
RISCV_EXCP_STORE_AMO_ADDR_MIS = 0x6, // 存储地址未对齐
RISCV_EXCP_STORE_AMO_ACCESS_FAULT = 0x7, // 存储访问错误
RISCV_EXCP_U_ECALL = 0x8, // 用户模式ECALL
RISCV_EXCP_S_ECALL = 0x9, // 超级用户模式ECALL
RISCV_EXCP_M_ECALL = 0xb, // 机器模式ECALL
RISCV_EXCP_INST_PAGE_FAULT = 0xc, // 指令页错误
RISCV_EXCP_LOAD_PAGE_FAULT = 0xd, // 加载页错误
RISCV_EXCP_STORE_PAGE_FAULT = 0xf, // 存储页错误
// ...
} RISCVException;
7.2.2 异常触发机制
方式一:TCG指令直接触发
// target/riscv/translate.c:257-262
static void generate_exception(DisasContext *ctx, RISCVException excp)
{
gen_update_pc(ctx, 0);
gen_helper_raise_exception(tcg_env, tcg_constant_i32(excp));
ctx->base.is_jmp = DISAS_NORETURN;
}
方式二:非法指令异常
// target/riscv/translate.c:264-273
static void gen_exception_illegal(DisasContext *ctx)
{
tcg_gen_st_i32(tcg_constant_i32(ctx->opcode), tcg_env,
offsetof(CPURISCVState, bins));
if (ctx->virt_inst_excp) {
generate_exception(ctx, RISCV_EXCP_VIRT_INSTRUCTION_FAULT);
} else {
generate_exception(ctx, RISCV_EXCP_ILLEGAL_INST);
}
}
使用案例:地址未对齐异常
// target/riscv/translate.c:275-279
static void gen_exception_inst_addr_mis(DisasContext *ctx, TCGv target)
{
tcg_gen_st_tl(target, tcg_env, offsetof(CPURISCVState, badaddr));
generate_exception(ctx, RISCV_EXCP_INST_ADDR_MIS);
}
7.2.3 Helper函数处理异常
当翻译的TCG代码执行到 helper_raise_exception 时:
// target/riscv/op_helper.c:46-63
G_NORETURN void riscv_raise_exception(CPURISCVState *env,
RISCVException exception,
uintptr_t pc)
{
CPUState *cs = env_cpu(env);
trace_riscv_exception(exception,
riscv_cpu_get_trap_name(exception, false),
env->pc);
cs->exception_index = exception;
cpu_loop_exit_restore(cs, pc); // 关键:退出当前TB并跳转到异常处理
}
void helper_raise_exception(CPURISCVState *env, uint32_t exception)
{
riscv_raise_exception(env, exception, 0);
}
7.3 外部中断处理
7.3.1 中断标志位定义
// target/riscv/cpu_bits.h:793-794
#define RISCV_EXCP_INT_FLAG 0x80000000 // 中断标志
#define RISCV_EXCP_INT_MASK 0x7fffffff // 掩码
// 中断类型定义
#define IRQ_U_SOFT 0 // 用户软件中断
#define IRQ_S_SOFT 1 // 超级用户软件中断
#define IRQ_M_SOFT 3 // 机器软件中断
#define IRQ_U_TIMER 4 // 用户定时器中断
#define IRQ_S_TIMER 5 // 超级用户定时器中断
#define IRQ_M_TIMER 7 // 机器定时器中断
#define IRQ_U_EXT 8 // 用户外部中断
#define IRQ_S_EXT 9 // 超级用户外部中断
#define IRQ_M_EXT 11 // 机器外部中断
7.3.2 中断处理流程
外部中断通过 cpu_handle_interrupt 函数处理:
// cpu-exec.c:779-884
static inline bool cpu_handle_interrupt(CPUState *cpu,
TranslationBlock **last_tb)
{
// 1. 检查是否有中断请求
if (unlikely(cpu_test_interrupt(cpu, ~0))) {
bql_lock();
if (cpu_test_interrupt(cpu, CPU_INTERRUPT_DEBUG)) {
cpu_reset_interrupt(cpu, CPU_INTERRUPT_DEBUG);
cpu->exception_index = EXCP_DEBUG;
bql_unlock();
return true;
}
if (cpu_test_interrupt(cpu, CPU_INTERRUPT_HALT)) {
replay_interrupt();
cpu_reset_interrupt(cpu, CPU_INTERRUPT_HALT);
cpu->halted = 1;
cpu->exception_index = EXCP_HLT;
bql_unlock();
return true;
}
// 2. 调用架构特定的中断处理
if (tcg_ops->cpu_exec_interrupt(cpu, interrupt_request)) {
// 处理完成后返回
cpu->exception_index = -1;
*last_tb = NULL;
}
bql_unlock();
}
// 3. 检查退出请求
if (unlikely(qatomic_load_acquire(&cpu->exit_request)) || icount_exit_request(cpu)) {
if (cpu->exception_index == -1) {
cpu->exception_index = EXCP_INTERRUPT;
}
return true;
}
return false;
}
7.3.3 CPU状态通知机制
中断请求标志:
// cpu-exec.c:728
tcg_ops->do_interrupt(cpu); // 在中断处理时被调用
外设触发中断流程:
外设中断源
↓
设置CPU的interrupt_request标志
↓
设置exit_request请求CPU退出当前TB
↓
cpu_handle_interrupt()检测到中断
↓
调用架构特定的do_interrupt()
↓
保存现场、切换到中断处理模式
7.4 核心退出机制:longjmp
QEMU使用 siglongjmp 实现从任意位置退出当前TB:
// accel/tcg/cpu-exec-common.c:60-75
void cpu_loop_exit(CPUState *cpu)
{
/* Undo the setting in cpu_tb_exec. */
cpu->neg.can_do_io = true;
/* Undo any setting in generated code. */
qemu_plugin_disable_mem_helpers(cpu);
siglongjmp(cpu->jmp_env, 1); // 跳转到cpu_exec的longjmp捕获点
}
void cpu_loop_exit_restore(CPUState *cpu, uintptr_t pc)
{
if (pc) {
cpu_restore_state(cpu, pc); // 恢复CPU状态到异常发生前
}
cpu_loop_exit(cpu);
}
执行流程:
helper_raise_exception()
↓
cpu_loop_exit_restore()
↓
siglongjmp(cpu->jmp_env, 1)
↓
[跳回 cpu_exec 的 sigsetjmp 捕获点]
↓
cpu_handle_exception()
↓
tcg_ops->do_interrupt(cpu) // 处理异常/中断
7.5 案例分析:RISC-V Ecall指令
7.5.1 指令功能
ECALL指令用于从低特权级切换到高特权级(如U -> S -> M)。
7.5.2 翻译实现
// target/riscv/insn_trans/trans_rvi.c
static bool trans_ecall(DisasContext *ctx, arg_ecall *a)
{
RISCVException excp;
if (a->mode == PRV_U) {
excp = RISCV_EXCP_U_ECALL;
} else if (a->mode == PRV_S) {
excp = RISCV_EXCP_S_ECALL;
} else if (a->mode == PRV_VS) {
excp = RISCV_EXCP_VS_ECALL;
} else {
excp = RISCV_EXCP_M_ECALL;
}
generate_exception(ctx, excp);
return true;
}
7.5.3 完整流程图
Guest执行ECALL指令
↓
TCG翻译:generate_exception(RISCV_EXCP_XXX_ECALL)
↓
TCG IR: helper_raise_exception(env, exception_id)
↓
执行helper_raise_exception()
↓
riscv_raise_exception()
↓
设置 cs->exception_index = exception_id
↓
cpu_loop_exit_restore(cs, pc)
↓
siglongjmp -> 返回cpu_exec主循环
↓
cpu_handle_exception()检测到异常
↓
tcg_ops->do_interrupt(cpu) // RISC-V特定处理
↓
保存当前PC到mepc寄存器
↓
根据mstatus确定新特权级
↓
设置mtval等CSR寄存器
↓
跳转到对应的异常处理向量
7.6 案例分析:外部定时器中断
7.6.1 中断触发路径
Host定时器触发
↓
QEMU定时器回调函数
↓
设置RISC-V的mip.MTIP位
↓
调用qemu_cpu_kick(cpu)请求CPU处理
↓
CPU执行流中检测到中断
7.6.2 代码实现
// 假设在hw/riscv/virt.c中
static void riscv_timer_cb(void *opaque)
{
RISCVCPU *cpu = opaque;
CPURISCVState *env = &cpu->env;
// 设置定时器中断挂起位
qatomic_set(&env->mip, MIP_MTIP);
// 通知CPU有中断
qemu_cpu_kick(CPU(cpu));
}
// 触发CPU中断处理
void qemu_cpu_kick(CPUState *cpu)
{
qatomic_store_release(&cpu->exit_request, true);
// ...
}
7.6.3 CPU中断处理
// cpu-exec.c:779-884
while (!cpu_handle_interrupt(cpu, &last_tb)) {
// 执行TB
tb = cpu_tb_exec(cpu, tb, &tb_exit);
}
// cpu_handle_interrupt内部
if (unlikely(cpu_test_interrupt(cpu, ~0))) {
// 测试各种中断源
if (cpu_test_interrupt(cpu, CPU_INTERRUPT_HALT)) {
// 处理HALT中断
}
// 调用架构特定的中断处理
tcg_ops->cpu_exec_interrupt(cpu, interrupt_request);
}
7.7 异常处理关键点
| 场景 | 触发方式 | 关键函数 | 退出机制 |
|---|---|---|---|
| 非法指令 | decode阶段检测 | gen_exception_illegal() | helper_raise_exception() |
| 页错误 | 内存访问时 | tcg_gen_qemu_ld/st | TLB未命中路径 |
| 系统调用 | ECALL指令 | generate_exception() | cpu_loop_exit_restore() |
| 外部中断 | 外设触发 | qemu_cpu_kick() | cpu_handle_interrupt() |
| 断点 | DEBUG触发 | EXCP_DEBUG | cpu_handle_debug_exception() |
7.8 总结
QEMU中断/异常机制的核心设计:
- 统一异常索引:
cpu->exception_index保存当前异常类型 - TCG辅助函数:
helper_raise_exception()实现从翻译代码中触发异常 - 长跳转机制:使用
siglongjmp从任意位置退出TB - 架构解耦:
tcg_ops->do_interrupt()抽象架构差异 - 中断通知:
interrupt_request和exit_request协调CPU响应中断
这种设计既保证了异常处理的灵活性,又最小化了性能开销。
8. 总结
核心概念回顾
| 组件 | 作用 | 关键文件 |
|---|---|---|
| TCG IR | 中间表示,guest与host解耦 | include/tcg/tcg-opc.h |
| SoftMMU | 地址翻译,TLB管理 | accel/tcg/cputlb.c |
| Backend | TCG IR到机器码 | tcg/x86_64/tcg-target.c.inc |
| Translator | Guest指令到TCG IR | target/riscv/tcg/translator-*.c |
| Exception/Interrupt | 异常处理机制 | accel/tcg/cpu-exec.c, op_helper.c |
进一步研究
- 性能优化: TB链接、指令缓存、寄存器分配优化
- 向量化: SIMD指令的TCG支持和向量寄存器映射
- 多线程: MTTCG (Multi-Threaded TCG) 实现
- 插件系统: QEMU plugin与TCG的交互
这个文档覆盖了QEMU TCG的核心架构。由于代码量很大,建议针对具体模块深入研究。
rust_vmm
gpu_in_qemu
k230_on_qemu
记录一下我在qemu平台上模拟 K230 soc, 并兼容使用 RustSbi 作为 Bios 启动的全流程。
最终成果:我们提交了相关patch: https://lore.kernel.org/qemu-devel/cover.1768884546.git.chao.liu.zevorn@gmail.com
我的工作记录:
初始状态
k230 soc具有两个cpu,我们主要模拟小核的启动的过程。
它基于risc-v指令集架构,目前主要的指令集和寄存器的扩展都已经实现(对于一些非risc-v规范的寄存器,读是返回0,写会被忽略)。 当前可以启动 k230 sdk 的 uboot,更具体的,查看此issuse。
既然能够启动官方的uboot,至少说明cpu的isa和寄存器实现没有太大问题。 uboot有相关输出,说明串口设备的实现也是没有问题的。
rustsbi 分析
官方地址是:https://github.com/rustsbi/rustsbi
我对rust还算熟悉,但是对rustsbi了解不深。 因为之前Arceos项目有用到rustsbi,所以对它的功能还算清楚:
- 它是运行在M态的一个二进制,
- 用类似于系统调用的方式提供了一些调用给S态的内核。
- 此外,它还有分发中断这类的作用。
但是rustsbi项目是如何组织的,以及怎么编译的,这块我是不太了解。不如先提出需求,然后拿着问题去看这个项目吧。
qemu-system-riscv64 \
-M k230 \
-nographic \
-device loader,file=k230_sdk/output/k230_canmv_defconfig/little/uboot/u-boot.bin,addr=0x8000000
需求分析
注意到启动命令固定的把uboot.bin放在了 0x8000000 的地方上。那么首先我们要把 rustsbi 也放在这个位置上看看。 这里就给出两个需求:
- 把rustsbi编译为bin
- rustsbi 的入口地址应该为 0x8000000
uboot能够输出,说明它肯定以某种方式获取了soc的串口地址。很显然,uboot可以认为是整个cpu上最先启动的程序,那么就没有别人和它说这个地址。 猜测它肯定是builtin了设备树,那么我们肯定也要把设备树增加到rustsbi中。
- 给 rustsbi 增加设备树
需求实现
通过阅读 rustsbi 文档,发现 prototyper 是我所需要的,
因为我就需要一个firmware。文档里也给出了编译fdt的办法,通过传递 --fdt $fdt_file 就可以。
修改rustsbi地址的话文档里就没有了,但是简单的来讲,肯定要去找linker script。因为像这种没有os的程序,肯定是在这里定义了.text段的地址。
在 prototyper/prototyper/build.rs 中 发现了链接脚本。
#![allow(unused)]
fn main() {
const LINKER_SCRIPT: &[u8] = b"OUTPUT_ARCH(riscv)
ENTRY(_start)
SECTIONS {
. = 0x80000000;
. = ALIGN(0x1000); /* Need this to create proper sections */
sbi_start = .;
.text : ALIGN(0x1000) {
*(.text.entry)
*(.text .text.*)
}
. = ALIGN(0x1000);
sbi_rodata_start = .;
.rodata : ALIGN(0x1000) {
*(.rodata .rodata.*)
*(.srodata .srodata.*)
. = ALIGN(0x1000);
}
.dynsym : ALIGN(8) {
*(.dynsym)
}
.rela.dyn : ALIGN(8) {
__rel_dyn_start = .;
*(.rela*)
__rel_dyn_end = .;
}
. = ALIGN(0x1000);
sbi_rodata_end = .;
/*
* PMP regions must be to be power-of-2. RX/RW will have separate
* regions, so ensure that the split is power-of-2.
*/
/* . = ALIGN(1 << LOG2CEIL((SIZEOF(.rodata) + SIZEOF(.text)
+ SIZEOF(.dynsym) + SIZEOF(.rela.dyn)))); */
.data : ALIGN(0x1000) {
sbi_data_start = .;
*(.data .data.*)
*(.sdata .sdata.*)
. = ALIGN(0x1000);
sbi_data_end = .;
}
sidata = LOADADDR(.data);
.bss (NOLOAD) : ALIGN(0x1000) {
*(.bss.stack)
. = ALIGN(0x1000);
sbi_heap_start = .;
*(.bss.heap)
sbi_heap_end = .;
. = ALIGN(0x1000);
sbi_bss_start = .;
*(.bss .bss.*)
*(.sbss .sbss.*)
sbi_bss_end = .;
}
/DISCARD/ : {
*(.eh_frame)
}
. = ALIGN(0x1000);
.text : ALIGN(0x1000) {
*(.fdt)
}
. = ALIGN(0x1000);
sbi_end = .;
.text 0x80200000 : ALIGN(0x1000) {
*(.payload)
}
}";
}不过一般来说,这种代码应该都是PIC的,也就是地址无关的。搜索 0x80000000 发现了 relocation_update 函数, 也确实发现了做了重定位。 所以需求1和2可能不需要做?需求三的话就很简单了,只需要在编译 prototyper 的时候加上 -fdt 参数就可以。
# 尝试不实现需求1和2,能不能把rustsbi跑起来
# 这个dtb从官方的sdk中找出来
$ cargo prototyper --fdt ./k230_canmv.dtb
$ cd ${qemu_k230} && ./build/qemu-system-riscv64 -M k230 -nographic -device loader,file=${rustsbi}/target/riscv64gc-unknown-none-elf/release/rustsbi-prototyper-dynamic.bin,addr=0x8000000
[RustSBI] INFO - Hello RustSBI!
[RustSBI] INFO - RustSBI version 0.4.0
[RustSBI] INFO - .______ __ __ _______.___________. _______..______ __
[RustSBI] INFO - | _ \ | | | | / | | / || _ \ | |
[RustSBI] INFO - | |_) | | | | | | (----`---| |----`| (----`| |_) || |
[RustSBI] INFO - | / | | | | \ \ | | \ \ | _ < | |
[RustSBI] INFO - | |\ \----.| `--' |.----) | | | .----) | | |_) || |
[RustSBI] INFO - | _| `._____| \______/ |_______/ |__| |_______/ |______/ |__|
[RustSBI] INFO - Initializing RustSBI machine-mode environment.
[RustSBI] INFO - Platform Name : kendryte k230 canmv
[RustSBI] INFO - Platform HART Count : 1
[RustSBI] INFO - Enabled HARTs : [0]
[RustSBI] WARN - Platform IPI Device : Not Available
[RustSBI] INFO - Platform Console Extension : Uart16550U32 (Base Address: 0x91400000)
[RustSBI] WARN - Platform Reset Device : Not Available
[RustSBI] WARN - Platform HSM Extension : Not Available
[RustSBI] WARN - Platform RFence Extension : Not Available
[RustSBI] WARN - Platform SUSP Extension : Not Available
[RustSBI] WARN - Platform PMU Extension : Not Available
[RustSBI] INFO - Memory range : 0x0 - 0x20000000
[RustSBI] INFO - Platform Status : Platform initialization complete and ready.
[RustSBI] INFO - PMP Configuration
[RustSBI] INFO - PMP Range Permission Address
[RustSBI] INFO - 0 OFF NONE 0x0000000000000000
[RustSBI] INFO - 1 TOR RWX 0x0000000000000000
[RustSBI] INFO - 2 TOR RWX 0x0000000008000000
[RustSBI] INFO - 3 TOR R 0x0000000008027000
[RustSBI] INFO - 4 TOR NONE 0x0000000008035000
[RustSBI] INFO - 5 TOR R 0x0000000008074000
[RustSBI] INFO - 6 TOR RWX 0x0000000020000000
[RustSBI] INFO - 7 TOR RWX 0xfffffffffffffffc
[RustSBI] INFO - Boot HART ID : 0
[RustSBI] INFO - Boot HART Privileged Version: : Version1_12
[RustSBI] INFO - Boot HART MHPM Mask: : 0x07ffff
[RustSBI] ERROR - No dynamic information available at address 0x0
QEMU: Terminated
可以! 确实看到输出了,这样我们就不用改rustsbi的代码,继续尝试后面的部分了!
一个坑
实际测的时候的时候肯定不会像文档这样简单。 所以我记录了最困扰的一个坑:栈溢出。 目前这个问题还没有fix,所以注意不要开启debug模式使用。 https://github.com/rustsbi/rustsbi/issues/172
start 官方 kernel + initd
如何编译官方sdk以及busybox就不再这里写出来了。 前者在官网上都有的,而后者借助ai等工具也是很简单的事情。不过为了尽可能的使用k230的扩展,要使用官方的compiler。
通过 –kernel 传递进去之后发现现象还是和之前一样, [RustSBI] ERROR - No dynamic information available at address 0x0,
查看代码发现这个是去读取了 a2寄存器(soc板卡初始化代码传递的参数),而boot代码很简单,只是设置了trap然后跳转到 0x8000000 而已。
/* Mask ROM reset vector */
uint32_t reset_vec[] = {
/* 0x91200000: auipc t0, 0x0 */ 0x00000297,
/* 0x91200004: addi t0, t0, 36 # <trap> */ 0x02428293,
/* 0x91200008: csrw mtvec, t0 */ 0x30529073,
/* 0x9120000C: csrr a0, misa */ 0x301012F3,
/* 0x91200010: lui t0, 0x1 */ 0x000012B7,
/* 0x91200014: slli t0, t0, 1 */ 0x00129293,
/* 0x91200018: and t0, a0, t0 */ 0x005572B3,
/* 0x9120001C: bnez t0, loop */ 0x00511063,
/* entry: */
/* 0x91200020: addiw t0, zero, 1 */ 0x0010029b,
/* 0x91200024: slli t0, t0, 0x1b */ 0x01b29293,
/* 0x91200028: jr t0 # uboot 0x8000000 */ 0x00028067,
/* loop: */
/* 0x9120002C: j 0x9120002C # <loop> */ 0x0000006f,
/* trap: */
/* 0x91200030: j 0x91200030 # <trap> */ 0x0000006f,
};
在k230.c中可以看到内存布局,,addr=0x8000000的作用是把 uboot/rustsbi 给搬到了这个地址上。也就是ram上。
static const MemMapEntry memmap[] = {
[K230_DEV_DDRC] = { 0x00000000, 0x80000000 },
[K230_DEV_KPU_L2_CACHE] = { 0x80000000, 0x00200000 },
...
}
rustsbi 支持 jump mode, 这样的话我们可以把jump的地址和kernel load的地址都统一掉。 就在我开启jump mode之后,尝试运行后qemu 出现了coredump。
碰到的问题一
这个问题具体来说是两个子问题:
- 使用 –bios 将 rustsbi.bin 传递参数,rustsbi也能正常启动 (–bios 默认把rustsbi放在内存起始的地方) @p1
- 自然的,我尝试开启了 -d in_asm 来打印指令,看看为什么能够正常启动,结果qemu 打印了一会儿之后 coredump 了 @p2
./build/qemu-system-riscv64 -M k230 -nographic --bios rustsbi/target/riscv64gc-unknown-none-elf/release/rustsbi-prototyper-jump.bin -d in_asm
...
----------------
IN:
0x0000b376: 6090 ld a2,0(s1)
0x0000b378: 6494 ld a3,8(s1)
0x0000b37a: 6c88 ld a0,24(s1)
0x0000b37c: 708c ld a1,32(s1)
0x0000b37e: 7498 ld a4,40(s1)
0x0000b380: 03048813 addi a6,s1,48
0x0000b384: ec2a sd a0,24(sp)
0x0000b386: f02e sd a1,32(sp)
0x0000b388: f43a sd a4,40(sp)
0x0000b38a: 01048793 addi a5,s1,16
0x0000b38e: 850a mv a0,sp
0x0000b390: 082c addi a1,sp,24
0x0000b392: 874a mv a4,s2
0x0000b394: ffff5097 auipc ra,-11 # 0x394
0x0000b398: 386080e7 jalr ra,ra,902
----------------
IN:
0x0000071a: Segmentation fault(核心已转储)
第一个子问题容易解决,问题在reset_vec的 /* 0x91200004: addi t0, t0, 36 # <trap> */ 0x02428293, 正确的偏移应该是 0x30, 也就是48,因为
trap的地址在 0x91200030。
不过解决了子问题1,就会spin 住了,之前能跑是因为异常后重新跳到了 slli t0, t0, 0x1b, 这个时候t0会循环进行若干次左移0x1b(别的地址上都没有数据,或者直接就是非法地址)。最终会跑到0x0地址上去。
第二个问题就有点复杂了,先上gdb吧。
(gdb) bt
#0 0x0000155553d8f33d in () at /usr/lib64/libc.so.6
#1 0x0000555555c3c715 in translator_st (db=0x155552dfb420, dest=0x155552dfb1f6, addr=1818, len=2) at ../accel/tcg/translator.c:428
#2 0x000055555589530e in translator_read_memory (memaddr=1818, myaddr=0x155552dfb1f6 "", length=2, info=0x155552dfb280)
at ../disas/disas-target.c:17
#3 0x00005555558941ce in print_insn_riscv (memaddr=1818, info=0x155552dfb280, isa=rv64) at ../disas/riscv.c:5479
#4 0x00005555558943e0 in print_insn_riscv64 (memaddr=1818, info=0x155552dfb280) at ../disas/riscv.c:5525
#5 0x000055555589544d in target_disas (out=0x155553df24c0 <_IO_2_1_stderr_>, cpu=0x555556a209c0, db=0x155552dfb420) at ../disas/disas-target.c:47
...
(gdb) frame 1
#1 0x0000555555c3c715 in translator_st (db=0x155552dfb420, dest=0x155552dfb1f6, addr=1818, len=2) at ../accel/tcg/translator.c:428
428 memcpy(dest, db->host_addr[0] + offset, len);
(gdb) p db->host_addr[0]
$1 = (void *) 0xe2e4d14c545dfa00
通过排查,发现是 translator_st 的 db->host_addr[0] 是一个奇怪的值。
通过调用栈可以看出最早出现在 tb_gen_code,下面是这个函数的部分实现。
TranslationBlock *tb_gen_code(CPUState *cpu, TCGTBCPUState s)
{
void *host_pc;
phys_pc = get_page_addr_code_hostp(env, s.pc, &host_pc);
// ...
if (phys_pc == -1) {
/* Generate a one-shot TB with 1 insn in it */
s.cflags = (s.cflags & ~CF_COUNT_MASK) | 1;
}
gen_code_size = setjmp_gen_code(env, tb, s.pc, host_pc, &max_insns, &ti);
// ...
}
qemu 的实现也是比较奇怪的,判断 phys_pc == -1 说明这个 get_page_addr_code_hostp 有可能失败,但却没有对 host_pc 赋初始值。 失败的时候也没有对 host_pc 进行处理,就导致 setjmp_gen_code 去访问一个栈上的随机地址,coredump就不奇怪了。
现在问题变成了,为什么 get_page_addr_code_hostp 会返回失败?@p3
不过在此之前,应该先把这个 host_pc 随机值的问题修改一下。无论如何,这是不够健壮的。
修改代码很简单,就一行
git diff accel/tcg/translate-all.c
diff --git a/accel/tcg/translate-all.c b/accel/tcg/translate-all.c
index d468667..035adf7 100644
--- a/accel/tcg/translate-all.c
+++ b/accel/tcg/translate-all.c
@@ -266,7 +266,7 @@ TranslationBlock *tb_gen_code(CPUState *cpu, TCGTBCPUState s)
tcg_insn_unit *gen_code_buf;
int gen_code_size, search_size, max_insns;
int64_t ti;
- void *host_pc;
+ void *host_pc = NULL;
assert_memory_lock();
qemu_thread_jit_write();
重新编译后,能够输出了。 现在来解决 p3: 通过 gdb 发现一条mmu中的 full->lg_page_size 为0,也就是1(2^0 = 1),那肯定是谁设置的了这种奇怪的pte。 继续gdb发现了这种设置,如下:
(gdb) bt
#0 tlb_set_page_with_attrs (cpu=0x555556a209c0, addr=1818, paddr=1818, attrs=..., prot=7, mmu_idx=3, size=1) at ../accel/tcg/cputlb.c:1190
#1 0x0000555555c415f4 in tlb_set_page (cpu=0x555556a209c0, addr=1818, paddr=1818, prot=7, mmu_idx=3, size=1) at ../accel/tcg/cputlb.c:1206
#2 0x0000555555cd9a43 in riscv_cpu_tlb_fill
(cs=0x555556a209c0, address=1818, size=1, access_type=MMU_INST_FETCH, mmu_idx=3, probe=false, retaddr=0) at ../target/riscv/cpu_helper.c:1876
#3 0x0000555555c41783 in tlb_fill_align (cpu=0x555556a209c0, addr=1818, type=MMU_INST_FETCH, mmu_idx=3, memop=MO_8, size=1, probe=false, ra=0)
at ../accel/tcg/cputlb.c:1257
#4 0x0000555555c41de8 in probe_access_internal
(cpu=0x555556a209c0, addr=1818, fault_size=1, access_type=MMU_INST_FETCH, mmu_idx=3, nonfault=false, phost=0x155552dfaf30, pfull=0x155552dfaf28, retaddr=0, check_mem_cbs=false) at ../accel/tcg/cputlb.c:1377
(gdb)
无他,继续gdb。最终定位到了PMP配置这边。
tlb_size = pmp_get_tlb_size(env, pa);
target_ulong pmp_get_tlb_size(CPURISCVState *env, hwaddr addr)
{
// ...
if (pmp_sa <= tlb_sa && pmp_ea >= tlb_ea) {
return TARGET_PAGE_SIZE;
} else if ((pmp_sa >= tlb_sa && pmp_sa <= tlb_ea) ||
(pmp_ea >= tlb_sa && pmp_ea <= tlb_ea)) {
return 1;
}
// ...
}
返回 1 的只有这里,所以继续深入发现这个 1818 这个地址传入的时候,最终会命中 PMP 区域1,这个区域 sa,ea 为 [0,0], 权限为RWX。 这样看起来是rustsbi设置的有问题了。查看启动日志,发现rustsbi pmp 配置如下:
[RustSBI] INFO - PMP Configuration
[RustSBI] INFO - PMP Range Permission Address
[RustSBI] INFO - 0 OFF NONE 0x0000000000000000
[RustSBI] INFO - 1 TOR RWX 0x0000000000000000
[RustSBI] INFO - 2 TOR RWX 0x0000000000000000
[RustSBI] INFO - 3 TOR R 0x0000000000027000
[RustSBI] INFO - 4 TOR NONE 0x0000000000035000
[RustSBI] INFO - 5 TOR R 0x0000000000074000
[RustSBI] INFO - 6 TOR RWX 0x0000000020000000
[RustSBI] INFO - 7 TOR RWX 0xfffffffffffffffc
有两个异常的配置,分别是 PMP 1和PMP 2。 查看rustsbi逻辑, 一次设置 {addr_start, SBI_START_ADDRESS, …}。 现在 addr_start 是0,SBI_START_ADDRESS也是0,所以就会出现异常的PMP config,让第一个page内的所有指令都没法正常访问。
看起来是rustsbi的问题,想办法修改一下。 不过整体来看,还是这个 0 地址过于特殊了,很多时候都不认为0是一个有效的地址。既然如此,我们skip掉第一个页的ram。
diff --git a/hw/riscv/k230.c b/hw/riscv/k230.c
index 48540e5..1d0afb4 100644
--- a/hw/riscv/k230.c
+++ b/hw/riscv/k230.c
@@ -395,7 +395,7 @@ static void k230_machine_done(Notifier *notifier, void *data)
K230MachineState *s = container_of(notifier, K230MachineState,
machine_done);
MachineState *machine = MACHINE(s);
- hwaddr start_addr = memmap[K230_DEV_DDRC].base;
+ hwaddr start_addr = memmap[K230_DEV_DDRC].base + 4096;
target_ulong firmware_end_addr, kernel_start_addr;
const char *firmware_name = riscv_default_firmware_name(&s->soc.c908_cpu);
uint64_t kernel_entry = 0;
@@ -407,7 +407,7 @@ static void k230_machine_done(Notifier *notifier, void *data)
/* Mask ROM reset vector */
uint32_t reset_vec[] = {
/* 0x91200000: auipc t0, 0x0 */ 0x00000297,
- /* 0x91200004: addi t0, t0, 0x30 # <trap> */ 0x02428293,
+ /* 0x91200004: addi t0, t0, 0x30 # <trap> */ 0x03028293,
/* 0x91200008: csrw mtvec, t0 */ 0x30529073,
/* 0x9120000C: csrr a0, misa */ 0x301012F3,
/* 0x91200010: lui t0, 0x1 */ 0x000012B7,
@@ -416,8 +416,8 @@ static void k230_machine_done(Notifier *notifier, void *data)
/* 0x9120001C: bnez t0, loop */ 0x00511063,
/* entry: */
/* 0x91200020: addiw t0, zero, 1 */ 0x0010029b,
- /* 0x91200024: slli t0, t0, 0x1b */ 0x01b29293,
- /* 0x91200028: jr t0 # uboot 0x8000000 */ 0x00028067,
+ /* 0x91200024: slli t0, t0, 0xc */ 0x00c29293,
+ /* 0x91200028: jr t0 # uboot 0x1000 */ 0x00028067,
/* loop: */
/* 0x9120002C: j 0x9120002C # <loop> */ 0x0000006f,
/* trap: */
device tree 修改
原来的k230.c中很多plic和clint的地址与spec/设备上对应不上,导致了rustsbi无法识别设备,打印出 [RustSBI] ERROR - SBI or IPI device not initialized 这样的日志,这里统一进行了修改。
start kernel
现在,可以开始通过 –kernel 参数把 编译好的kernel 传入。
-
jump address 调整 不过需要注意的是,rustsbi jump默认跳转到 0x80200000, 可以在 default.toml 中定义并修改。 现在我们把rustsbi 放在 0x1000的位置,qemu会把kernel放在bios之后,并按照0x200000(64位)进行对齐。 rustsbi的大小没有超过 0x200000,所以kernel就在也就是 0x200000 的地方。
-
巧用qemu调试
关于 qemu 的调试方法,需要包括 trace, monitor, gdb-stub 等等方法,这里给出一个社区link,可以在这儿进行查看。
通过上面的方法,我发现了原先实现中一些问题,包括:
- isa中 mmu 扩展没有开启,导致kernel va -> pa 失败
- isa中 pte 扩展位没有开启,导致qemu翻译va失败
- chardev 实现不完全,导致kernel probe的时候失败
-
kernel参数调整 启动参数默认使用串口进行通信。但很可能串口本身就有一定的问题(qemu实现的问题/驱动问题),这个时候使用 sbi 作为早期串口输出,是一个很好的办法,可以让kernel尽可能的输出一些有效信息。通过在设备树 bootargs 中增加
earlycon=sbi(需要sbi支持),就可以让kernel打印出早期的panic信息。
[RustSBI] INFO - Boot HART MHPM Mask: : 0x07ffff
[RustSBI] INFO - The patched dtb is located at 0x5c000 with length 0x840.
[RustSBI] INFO - Redirecting hart 0 to 0x00000000200000 in Supervisor mode.
[ 0.000000] Linux version 5.10.4 (root@312917a475fa) (riscv64-unknown-linux-gnu-gcc (Xuantie-900 linux-5.10.4 glibc gcc Toolchain V2.6.0 B-20220715) 10.2.0, GNU ld (GNU Binutils) 2.35) #1 SMP Fri Dec 12 16:28:40 CST 2025
[ 0.000000] OF: fdt: Ignoring memory range 0x0 - 0x200000
[ 0.000000] earlycon: sbi0 at I/O port 0x0 (options '')
[ 0.000000] printk: bootconsole [sbi0] enabled
[ 0.000000] efi: UEFI not found.
[ 0.000000] cma: Reserved 204 MiB at 0x0000000013400000
[ 0.000000] Zone ranges:
[ 0.000000] DMA32 [mem 0x0000000000200000-0x000000001fffffff]
[ 0.000000] Normal empty
[ 0.000000] Movable zone start for each node
[ 0.000000] Early memory node ranges
[ 0.000000] node 0: [mem 0x0000000000200000-0x000000001fffffff]
[ 0.000000] Initmem setup node 0 [mem 0x0000000000200000-0x000000001fffffff]
[ 0.000000] Unable to handle kernel paging request at virtual address ffffffdfffe5c001
[ 0.000000] Oops [#1]
[ 0.000000] Modules linked in:
[ 0.000000] CPU: 0 PID: 0 Comm: swapper Not tainted 5.10.4 #1
[ 0.000000] epc: ffffffe00063b1d6 ra : ffffffe000024b18 sp : ffffffe001203f50
[ 0.000000] gp : ffffffe0013b8f08 tp : ffffffe00120c2c0 t0 : ffffffe012afefc0
[ 0.000000] t1 : 0000000100000000 t2 : 0000000000000001 s0 : ffffffe001203f60
[ 0.000000] s1 : ffffffdfffe5c000 a0 : ffffffdfffe5c000 a1 : ffffffe001212a30
[ 0.000000] a2 : 0000000000000000 a3 : 0000000000000000 a4 : 0000000000000000
[ 0.000000] a5 : ffffffdfffe00000 a6 : 0000000000000040 a7 : 0000000000000030
[ 0.000000] s2 : ffffffe0013bc0a8 s3 : 0000000000000000 s4 : ffffffe0013bc060
[ 0.000000] s5 : 0000000000000000 s6 : 0000000000000000 s7 : 0000000000000000
[ 0.000000] s8 : 0000000000000000 s9 : 0000000000000000 s10: 0000000000000000
[ 0.000000] s11: 0000000000000000 t3 : 0000000000000000 t4 : 0000000020000000
[ 0.000000] t5 : 0000000000000000 t6 : 0000000000000018
[ 0.000000] status: 0000000200000100 badaddr: ffffffdfffe5c001 cause: 000000000000000d
[ 0.000000] random: get_random_bytes called from oops_exit+0x30/0x58 with crng_init=0
[ 0.000000] ---[ end trace 0000000000000000 ]---
[ 0.000000] Kernel panic - not syncing: Attempted to kill the idle task!
[ 0.000000] ---[ end Kernel panic - not syncing: Attempted to kill the idle task! ]---
像这里,就可以看到kernel的panic。原因是在访问rustsbi提供dtb的时候panic了。 最终定位到原因应该是官方sdk给出的kernel版本较低,没法处理dtb地址在 load_pa 之前的情况。
- 修改qemu设备树逻辑和 –initd 支持
在前期这么多的工作进行之后,我们终于能够把看到典型的没有fs的报错。现在我们要给 k230 同时增加 –initrd 和 –dtb 支持。
接下来的工作是十分 straight forward的:
- 从 virt.c 中抄加载代码
- 把 dtb 的地址传递给rustsbi
- 让rustsbi不要patch dtb,把qemu patch过的dtb传递给qemu就可以。
[ 1.727027] sdhci: Secure Digital Host Controller Interface driver
[ 1.727234] sdhci: Copyright(c) Pierre Ossman
[ 1.727391] sdhci-pltfm: SDHCI platform and OF driver helper
[ 1.729053] ledtrig-cpu: registered to indicate activity on CPUs
[ 1.731204] usbcore: registered new interface driver usbhid
[ 1.731423] usbhid: USB HID core driver
[ 1.735991] NET: Registered protocol family 10
[ 1.757214] Segment Routing with IPv6
[ 1.758823] sit: IPv6, IPv4 and MPLS over IPv4 tunneling driver
[ 1.766306] NET: Registered protocol family 17
[ 1.768077] lib80211: common routines for IEEE802.11 drivers
[ 1.771520] 9pnet: Installing 9P2000 support
[ 1.772414] Key type dns_resolver registered
[ 1.774363] Loading compiled-in X.509 certificates
[ 1.825022] VFS: Cannot open root device "(null)" or unknown-block(0,0): error -6
[ 1.825256] Please append a correct "root=" boot option; here are the available partitions:
[ 1.826495] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
[ 1.827314] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 5.10.4 #1
[ 1.827763] Call Trace:
[ 1.828194] [<ffffffe000203baa>] walk_stackframe+0x0/0xaa
[ 1.828458] [<ffffffe000acdc90>] show_stack+0x32/0x3e
[ 1.828591] [<ffffffe000ad25a6>] dump_stack+0x76/0x90
[ 1.828721] [<ffffffe000acde46>] panic+0xfc/0x2b2
[ 1.828895] [<ffffffe000003252>] mount_block_root+0x1b6/0x24e
[ 1.829042] [<ffffffe0000033ea>] mount_root+0x100/0x12a
[ 1.829178] [<ffffffe00000354a>] prepare_namespace+0x136/0x16c
[ 1.829325] [<ffffffe000002e34>] kernel_init_freeable+0x1b2/0x1ce
[ 1.829503] [<ffffffe000adaf8e>] kernel_init+0x12/0x100
[ 1.829635] [<ffffffe000201b4a>] ret_from_exception+0x0/0xc
[ 1.831423] ---[ end Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) ]---
- gdb 调试 relocate 文件 由于kernel,sbi这种可执行文件都存在加载地址和链接地址不一致的情况。对于简单的线性映射,在gdb调试时可以通过重新add-symbol-file来实现。具体如下:
# offset = run_addr - link_addr
(gdb) set $offset = 0x200000 - 0xffffffe000000000
# remove old symbol file
(gdb) symbol-file
(gdb) add-symbol-file /apps/jp/k230_sdk/output/k230_canmv_defconfig/little/linux/vmlinux -o $offset
add symbol table from file "/apps/jp/k230_sdk/output/k230_canmv_defconfig/little/linux/vmlinux" with all sections offset by 0x2000200000
(y or n) y
- 一些妥协
-
一些 page flags 的忽略
t-head 在pte中设计了一些独有的flag,为了提高内存效率。不过需要控制开启额外的 m态 的 csr,详见玄铁spec。 在不开启相关配置的时候,这些位无效。所以官方sdk默认置位了这些位,但这些位与risc-v的部分位定义冲突,同样的 也与qemu softmmu冲突。所以为了简单,我们把sdk中下面这些高位全部改为了0。
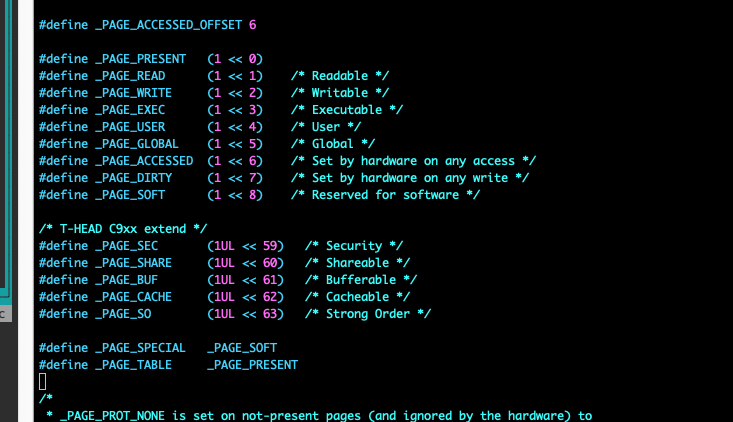
-
串口设备妥协
/* Offsets for the DesignWare specific registers */ #define DW_UART_DLF 0xc0 /* Divisor Latch Fraction Register */ #define DW_UART_CPR 0xf4 /* Component Parameter Register */ #define DW_UART_UCV 0xf8 /* UART Component Version */sdk 中的驱动会访问串口设备的这三个寄存器, 串口本身是 compatible = “snps,dw-apb-uart”。 qemu对这个设备的实现只有最基础的一些寄存器,导致访问这些寄存器的时候kernel会panic。 由此我们直接创建了一个unimp设备,这样读返回0,也符合标准。
-
vm_write_in_rust
写一个简单的VM,类似于JVM,使用 LC-3 架构,参考文档 https://www.jmeiners.com/lc3-vm/
项目地址
https://github.com/fkcrazy001/lc3vm.git
# to play 2048 game:
cargo run -- ./2048.obj
LC-3 架构
当我们研究一个新的VM时,内存模型,指令集 这些指标是我们需要关注的。
- 内存: 地址范围 128K, 位宽 16bit
- Cpu
-
寄存器: 8个16位的通用寄存器(R0-R7),1个PC,一个FLAG寄存器
-
opCode:
OP_BR = 0, /* branch */ OP_ADD, /* add */ OP_LD, /* load */ OP_ST, /* store */ OP_JSR, /* jump register */ OP_AND, /* bitwise and */ OP_LDR, /* load register */ OP_STR, /* store register */ OP_RTI, /* unused */ OP_NOT, /* bitwise not */ OP_LDI, /* load indirect */ OP_STI, /* store indirect */ OP_JMP, /* jump */ OP_RES, /* reserved (unused) */ OP_LEA, /* load effective address */ OP_TRAP /* execute trap */
-
实现时,需要具体的查看[1], 详细的描述的操作码,地址空间,异常等。
定义Vm
现在,我们可以定义Vm了
#![allow(unused)]
fn main() {
pub trait AddessSpace: Send {
fn write(&self, addr: u16, value: u16);
fn read(&self, addr: u16) -> u16;
}
pub struct Vm<A: AddessSpace> {
pub cpu: Cpu,
pub addess_space: A,
}
use bitflags::bitflags;
bitflags! {
pub struct Cond:u16 {
const FL_POS = 1 << 0; /* P */
const FL_ZRO = 1 << 1; /* Z */
const FL_NEG = 1 << 2; /* N */
}
}
pub struct Cpu {
pub regs: [u16; 8],
pub pc: u16,
pub cond: Cond,
}
}跑 hello world!
这是官方给出的汇编示例。
.ORIG x3000 ; this is the address in memory where the program will be loaded
LEA R0, HELLO_STR ; load the address of the HELLO_STR string into R0
PUTs ; output the string pointed to by R0 to the console
HALT ; halt the program
HELLO_STR .STRINGZ "Hello World!" ; store this string here in the program
.END ; mark the end of the file
假设已经有了汇编器,最终这些汇编汇编会被翻译成机器码。
现在需要实现一下机器码的解析。
opcode 解析
按照 [1] 中 A.3 The Instruction Set 来实现
opcode遵循下面的规则,具体的还是需要 case by case的分析
.... ............
opcode further_information
直接翻译
简单的来说,就是读取一个 u16 字节,然后获取opcode,根据这个 opcode 进行翻译。 举个例子:
ADD DR,SR1,SR2 对应的机器码为
0001 ... ... 0 00 ...
DR SR1 SR2
#![allow(unused)]
fn main() {
impl Cpu {
fn decode(&mut self, opcode:u16) {
let code = opcode >> 12;
match code {
0b0001 => {
let dr = (opcode >> 9) & 0x7;
let sr1 = (opcode >> 6) & 0x7;
assert_eq!(0,(opcode>>3) & 0x7);
let sr2 = opcode & 0x7;
self.regs[dr as _] = self.regs[sr1 as _] as _ + self.regs[sr2 as _];
// update N,P,Z flags
}
}
}
}
}将上面提到的指令,全部翻译完,就可以了。
tcg?
先去调研一下tcg的机制
TRAP 处理
由于lc3没有外设,所以这里 TRAP 更像是系统调用。简单的来说,就是提供了一些函数给 S 态的程序使用,包括输入输出字符串。 这里就通过 io::stdin(), io::stdout() 来获取了。
中断处理
LC3 从 0x180~0x1ff 分配给了外部中断,不过目前只有 keyboard 中断。待实现。
内存读写
简单的来说,就是实现AddessSpace trait。
#![allow(unused)]
fn main() {
impl AddessSpace for Lc3AddrSpace {
fn read(&self, addr: u16) -> u16 {
// let addr = addr << 1;
// println!("read addr: {addr:x}");
let res = match addr {
Self::InterruptVectorMax..Self::RamMax => {
let ram = self.mem.borrow();
ram[addr as usize]
}
Self::M_KBSR => {
// println!("read kbsr");
self.check_keyboard();
let ram = self.mem.borrow();
ram[addr as usize]
}
Self::MR_KBDR => {
self.write(Self::M_KBSR, 0);
let ram = self.mem.borrow();
ram[addr as usize]
}
_ => todo!("addr {addr:x} read!"),
};
// println!("read addr: {addr:x} ,value {res:x}");
res
}
fn write(&self, addr: u16, value: u16) {
// let addr = addr << 1;
// println!("write addr: {addr:x}, value {value:x}");
match addr {
Self::InterruptVectorMax..Self::RamMax | Self::M_KBSR | Self::MR_KBDR => {
let mut ram = self.mem.borrow_mut();
ram[addr as usize] = value;
}
_ => todo!("addr {addr:x} write!"),
}
}
}
}需要注意的是,lc3有两个特殊的MMIO寄存器,地址分别是 MR_KBSR(0xfe00), MR_KBDR(0xfe02)。
前者用于表示当前键盘是否有输入,如果有,那么最高位为1,否则为0。
后者用于表示当前键盘的输入值,只有当 MR_KBSR 的最高位为1时才有效果。读取这个寄存器会将 MR_KBSR 的寄存器最高位清0。
参考文档
ai-tech
ai_agent
从零开始,基于项目 https://github.com/datawhalechina/hello-agents 开始学习agent相关内容。
web3
监控
grafana
算法
线段树 (Segment Tree)
理解的不多了,只知道这是一个用来处理数组 区间查询 和 区间修改 的高级数据结构。 相比于普通数组 \( O(N) \) 的修改或查询复杂度,线段树可以将这两者都优化到 \( O(\log N) \)。
问题描述
有一个长度为 \( N \) 的数组 arr (\( 0 \dots N-1 \))。
我们需要频繁进行以下两种操作:
- 单点修改:将
arr[i]的值修改为 \( v \)。 - 区间查询:计算
arr[L,R]之间的和(或者最大值、最小值等)。
如果不使用线段树:
- 直接数组:修改 \( O(1) \),查询 \( O(N) \)。
- 前缀和:修改 \( O(N) \),查询 \( O(1) \)。
线段树可以使两者均为:
\[ O(\log N) \]
算法
线段树本质上是一棵 二叉树。
- 根节点表示整个区间 \( [0, N-1] \)。
- 每个节点代表一个区间 \( [L, R] \),其左子节点代表 \( [L, mid] \),右子节点代表 \( [mid+1, R] \)。
- 叶子节点代表单点 \( [i, i] \)。
通常使用 4倍大小的数组 tree 来存储这棵树。
# 假设 arr 长度为 N
# tree 数组长度通常开到 4 * N
tree = [0] * (4 * N)
# 1. 建树 (Build)
# node: 当前树节点下标 (从1开始), start/end: 当前节点对应的区间范围
def build(node, start, end):
if start == end:
tree[node] = arr[start]
return
mid = (start + end) // 2
left_node = node * 2
right_node = node * 2 + 1
build(left_node, start, mid)
build(right_node, mid + 1, end)
# Push Up: 当前节点的值等于左右子节点值的聚合(这里以求和为例)
tree[node] = tree[left_node] + tree[right_node]
# 2. 单点修改 (Update)
# 将 arr[idx] 修改为 val
def update(node, start, end, idx, val):
if start == end:
tree[node] = val
return
mid = (start + end) // 2
left_node = node * 2
right_node = node * 2 + 1
if idx <= mid:
update(left_node, start, mid, idx, val)
else:
update(right_node, mid + 1, end, idx, val)
# 修改完子节点后,记得更新当前节点
tree[node] = tree[left_node] + tree[right_node]
# 3. 区间查询 (Query)
# 查询区间 [L, R] 的和
def query(node, start, end, L, R):
# 如果当前节点区间完全包含在查询区间内,直接返回
if L <= start and end <= R:
return tree[node]
mid = (start + end) // 2
left_node = node * 2
right_node = node * 2 + 1
res = 0
# 如果左子区间和 [L, R] 有交集
if L <= mid:
res += query(left_node, start, mid, L, R)
# 如果右子区间和 [L, R] 有交集
if R > mid:
res += query(right_node, mid + 1, end, L, R)
return res
证明 (原理)
线段树利用了 分治 (Divide and Conquer) 的思想。
- 结构:我们将一个大区间不断二分,直到长度为1。这就构成了一棵高度为 \( \lceil \log_2 N \rceil \) 的二叉树。
- 覆盖:任意一个区间 \( [L, R] \),都可以被分解为线段树上不超过 \( 2 \log N \) 个节点的并集。
- 例如查询 \( [0, 5] \),可能会被拆分为节点 \( [0, 3] \) 和节点 \( [4, 5] \) 的组合。
- 复杂度:
- Build: 树的节点总数约为 \( 2N \) (甚至更接近 \( 4N \) 的存储空间),每个节点访问一次,复杂度 \( O(N) \)。
- Update: 从根走到叶子,深度为 \( \log N \),路径上的节点都需要更新,复杂度 \( O(\log N) \)。
- Query: 每一层最多访问 2-4 个节点(因为我们只关心重叠部分),总共访问 \( O(\log N) \) 个节点。
进阶优化:Lazy Propagation (懒标记)
如果需要 区间修改 (例如将 \( [L, R] \) 范围内的所有数都 +1),单点修改的方法会退化成 \( O(N) \)。 为了保持 \( O(\log N) \),引入 懒标记 (Lazy Tag)。
原理:
- 当修改一个区间 \( [L, R] \) 时,如果当前节点完全包含在 \( [L, R] \) 内,我们只更新当前节点的值,并打上一个标记
lazy[node],表示 “下面的子节点还没更新,先欠着”。 - 不下放:除非下次查询或修改需要进入该节点的子节点,否则这个标记一直保留。
- 下放 (Push Down):一旦需要进入子节点,就将当前的标记传给左右子节点,并清除当前标记。
# 伪代码逻辑
def push_down(node, start, end):
if lazy[node] != 0:
mid = (start + end) // 2
# 下放标记给左子节点
lazy[node*2] += lazy[node]
tree[node*2] += lazy[node] * (mid - start + 1)
# 下放标记给右子节点
lazy[node*2+1] += lazy[node]
tree[node*2+1] += lazy[node] * (end - mid)
#以此类推...
lazy[node] = 0
Floyd 算法
理解的不多了,目前只知道这个算法是用来算 有向图/无向图 中每个点到其它每个点的最短距离。 和 dijkstra 算法很像,不过后者是算单点到单点的,而且后者没法处理负权边。
问题描述
有 N 个点(0..n-1),g[N][N] 是一个有向图,其中 g[i][j] == inf 说明这两个点之间没有直接连接, 其他情况则说明有一条有向边,权重为 g[i][j] (正负都可以)
需要给出 cost[N][N], 其中 cost[i][j] 为从i点到j点需要的最短距离。
算法
# 初始状态
cost = g
for k in range(N):
for i in range(N):
for j in range(N):
cost[i][j] = min(cost[i][j], cost[i][k],cost[k][j])
证明
设置 dp 为 [k][i][j] 的数组,其中 0<= i,j,k < n
k 表示使用前面k个点的情况下,使得点i到点j的最短距离。
那么很显然,当 k = 0 时, dp[0][i][j] = g[i][j]
当 k > 0时, dp[k][i][j] =
- 要么不使用新加入节点 k-1,这种情况下最短距离为 dp[k-1][i][j]
- 要么使用新加入的节点 k-1,这种情况下,最短距离为 dp[k-1][i][k-1] + dp[k-1][k-1][j]
由此,k > 0是,dp[k][i][j] = min(dp[k-1][i][j], dp[k-1][i][k-1] + dp[k-1][k-1][j])
空间优化
dp[k] 明显只与 dp[k-1] 状态有关,所以这里可以做一次空间优化。
# 0<= k < n, 0<= i < n, 0<= j < n
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k][j])
Dijkstra 算法
这个算法是用来算 有向图/无向图 中 单点(源点) 到其它每个点的最短距离。 和 Floyd 算法不同,Dijkstra 不能处理负权边。
问题描述
有 \( N \) 个点(\( 0 \dots N-1 \)),\( g[N][N] \) 是一个有向图(邻接矩阵),其中 \( g[i][j] = \infty \) 说明这两个点之间没有直接连接。 其他情况则说明有一条有向边,权重为 \( g[i][j] \) (必须非负, \( g[i][j] \ge 0 \))。 给定一个源点 \( start \)。
需要给出 \( dist[N] \), 其中 \( dist[i] \) 为从 \( start \) 点到 \( i \) 点需要的最短距离。
算法
# 初始状态
# dist 数组记录从 start 到各个点的当前已知最短距离
dist = [inf] * N
dist[start] = 0
# visited 数组标记哪些点的最短路径已经被最终确定
visited = [False] * N
for _ in range(N):
# 1. 贪心策略:在所有未确定的点中,找到距离 start 最近的点 u
u = -1
min_val = inf
for i in range(N):
if not visited[i] and dist[i] < min_val:
min_val = dist[i]
u = i
# 如果找不到可达的点了,提前结束
if u == -1: break
# 2. 标记确定:点 u 的最短路径已经确定,不可再更改
visited[u] = True
# 3. 松弛操作 (Relaxation):借由点 u,更新所有邻居 v 的距离
for v in range(N):
if not visited[v] and g[u][v] != inf:
# 如果经由 u 到达 v 比直接去 v 更近,则更新
dist[v] = min(dist[v], dist[u] + g[u][v])
证明
Dijkstra 基于 贪心选择性质。 维护两个集合:\( S \) (已确定最短路的点集) 和 \( Q \) (未确定点集)。 算法的核心是:每次从 \( Q \) 中选出一个距离 \( start \) 最近的点 \( u \),它的最短路径即被视为确定。
证明关键点:为什么选出的 \( u \) 一定是全局最短?
使用反证法:
- 假设存在另一条从 \( start \) 到 \( u \) 的路径比当前的
dist[u]更短。 - 这条路径必然经过 \( Q \) 中的某个节点(因为起点在 \( S \),终点 \( u \) 在 \( Q \))。设路径上第一个属于 \( Q \) 的节点为 \( v \)。
- 路径形式为:\( start \to \dots \to v \to \dots \to u \)。
- 因为边权非负,且 \( v \) 是路径上的点,所以 \( start \to \dots \to v \) 的距离 (\( dist[v] \)) 必然 \( \le \) 整条路径长度。
- 根据贪心选择,\( u \) 是 \( Q \) 中距离最小的,所以 \( dist[u] \le dist[v] \)。
- 结合第4、5点,得出:整条“更短”路径长度 \( \ge dist[v] \ge dist[u] \)。
- 这与假设(存在比
dist[u]更短的路径)矛盾。
因此,dist[u] 就是最短距离。如果存在负权边,第4步推导失效,证明不成立。
时间优化
基础算法在寻找 \( u \) 时需要遍历 \( N \) 次,总复杂度 \( O(N^2) \)。 可以使用 优先队列 (Min-Heap) 优化查找最小值的过程,将复杂度降为 \( O(E \log N) \) (\( E \) 为边数),适合稀疏图。
import heapq
# graph 使用邻接表: graph[u] = [(v, weight), ...]
pq = [(0, start)] # 堆中存储 (distance, node)
dist = [inf] * N
dist[start] = 0
while pq:
d, u = heapq.heappop(pq) # O(log N)
if d > dist[u]: continue # 懒删除:如果取出的距离比已知的还大,丢弃
for v, weight in graph[u]:
if dist[u] + weight < dist[v]:
dist[v] = dist[u] + weight
heapq.heappush(pq, (dist[v], v)) # O(log N)
DSU & kruskal
DSU 并查集
适用场景:
- 查询两个集合是否有交集,如果有交集,那么将两个集合合并为1个。
- 查询一个元素是否在集合中,以及parent是谁。
算法:
class DSU:
# len(parent) == 大集合中
def __init__(self, parent):
# parent[i] = i
self.parent=parent
def find(self,x):
if self.parent[x] == x:
return x
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def jion(self,x,y):
px,py = self.find(x),self.find(y)
# 这里顺序不重要,只要共同指向一个祖先就行了。
self.parent[px] = py
kruskal 最小/大生成树
问题描述:
从一个由 n-1 个点形成的 无向图 [(Ui,Vi,Wi)] 中选出 n-1 条边,形成的一棵树,使得形成这棵树的代价最小/最大。
这棵树的代价是 所有边 之和。
算法实现:
将无向图按照 Wi 进行排序,构造一个已经加入这棵树的边集合。依此从排好序的图中选出 (u,v,w), 如果 u,v 构成的边在集合中没有环路,那么将这条边加入这个树中,总构造成本加上w。 集合中的元素达到n-1时,树构造完成。
# 集合使用 DSU 实现
def minBuildTree(graph:List[List[]], n:int) -> int:
dsu = DSU(list(range(n)))
graph.sort(key=lambda x: x[2])
cost = 0
np = 0
for u,v,w in graph:
if dsu.find(u) == dsu.find(v):
# node u and v already in dsu, skip
continue
cost+=w
dsu.jion(u,v)
np+=1
if np == n-1:
break
return cost if np == n-1 else -1
模逆元
模意义下乘法运算的逆元,并讨论它的常见求解方法。
概念引入
乘法/加法/减法 对于模运算都有 分配律 ,也就是说对于
$$ (A*B*C) \bmod mo == ((A \bmod mo)*(B \bmod mo)*(C \bmod mo))\ \bmod mo $$
这样的好处是 A * B * C 很有可能会超过数据范围,而取模之后再做乘法,就不会超过数据范围了。
但是对于除法,这个定律就不成立,也就是说 $$ (A \div B) \bmod mo \neq (A \bmod mo) \div (B \bmod mo) $$
由此引入 模逆元 定义, 将除法转变为乘法。
定义
模逆元: 对于一个数 a,如果存在b使得 $$ab === 1 (\bmod m)$$ 就说b是a在模m意义下的逆元。
前提: 有解的前提是 gcd(a,m) == 1, 且这个解在[0,m-1] 范围内仅存在一个。 关于这个证明,看这里 https://oi-wiki.org/math/number-theory/linear-equation/ 。
算法
用到了扩展欧几里得算法。
# Extended Euclidean algorithm.
def ex_gcd(a, b):
if b == 0:
return 1, 0
else:
x1, y1 = ex_gcd(b, a % b)
x = y1
y = x1 - (a // b) * y1
return x, y
# Returns the modular inverse of a modulo m.
# Assumes that gcd(a, m) = 1, so the inverse exists.
def inverse(a, m):
x, y = ex_gcd(a, m)
return (x % m + m) % m